Earlier this month a new research paper was released, which extensively tested capabilities of Large Language Models (LLMs) at a particular class of questions around temporal attributes. This paper is a really good read and confirms some of the suspicions us GenAI practitioners have about using an LLM for complex mathematical operations - they’re just not that accurate.
The summary of this paper is as follows:
-
The test was conducted with a few state-of-the-art models [GPT-4-turbo, Claude Sonnet and Gemini-Pro] do a below average job when presented with facts with temporal attributes. The accuracy is between 40% for complex tasks to 92% for simpler tasks.
-
As the dataset becomes more complex, the accuracy of the responses goes down.
-
The accuracy of the responses also goes down when the complexity of the arithmetic required to compute the answer goes up.
Does this mean that we should abandon the use of LLMs for data analysis tasks especially around temporal attributes? Not necessarily, read on for more.
Let’s look at the research in a bit more detail
The approach in this experiment was very well structured:
-
The datasets used for the research were synthetically generated to prevent the LLM from relying on its past knowledge
-
The datasets were organized into different types of graphs to demonstrate relationships between different entities
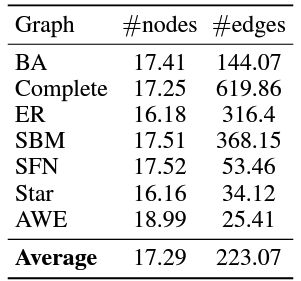 Different graph structures used for ToT tests
Different graph structures used for ToT tests
Graph based structure for ToT tests
The questions themselves were of various categories to comprehensively test various different scenarios across semantic questions and arithmetic questions
 Semantic question categories
Semantic question categories
Semantic question categories
 Arithmetic ToT question categories
Arithmetic ToT question categories
Arithmetic ToT question categories
The results:
- The overall accuracy for different types of questions was vastly different. In the Semantic dataset, Gemini Pro had a slight edge over gpt-4-turbo:
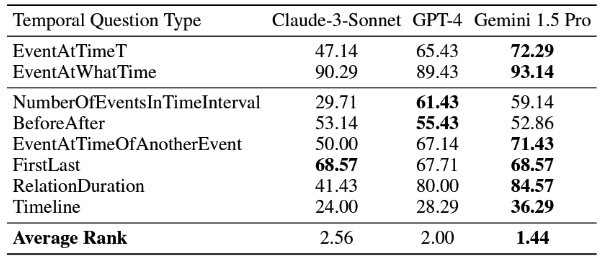 ToT Semantic LLM results
ToT Semantic LLM results
ToT Semantic LLM results
2. For the arithmetic dataset, gpt-4-turbo was better:
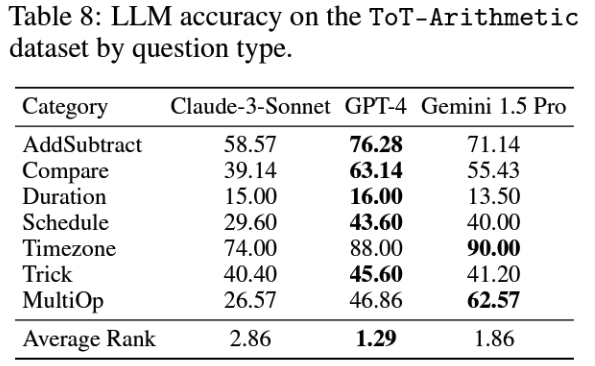 ToT Arithmetic LLM results
ToT Arithmetic LLM results
ToT Arithmetic LLM results
While the results vary significantly from one test to the other, what stands out is this: in both of these you can see that the accuracy is wildly differing and not exactly encouraging.
16% accuracy for “duration” accuracy questions on a graph isn’t ready for production!
Does this mean that we should abandon the use of LLMs for use cases around temporal data? Not really. Here are some insights from us after a year and a half of working with large datasets and building LLM applications on temporal data.
The key misconception that needs to be addressed: You cannot simply prompt your way to better AI software
This particular paper is a great example of the biggest misconception that’s going around today around Gen AI: That you can completely replace large modules of your software with just an LLM prompt. This is a strategy that will work during the MVP stage of product development, but will fail when you’re trying to deploy to production. Replacing key modules of a data analysis software with a single large prompt is a sure shot recipe for failure.
There is still a key need for developing your AI modules around well anchored logic as well as blending it with more “traditional” software engineering approaches.
If you have to use AI for number crunching on a large temporal based dataset on the fly, it’s much better to do so by first providing some software-first modules like a MongoDB agent to break down the dataset into more consumable content
There’s a specific reason why ChatGPT defaults to using CodeInterpreter. Quant based questions like those in this paper, that cannot rely exclusively on parametric memory are better served with Python programs on the fly than using a “brute force” approach.
Agentic frameworks can drive up accuracy significantly…
The results in the research show an accuracy that’s varying between 20% to 90% for temporal questions of different types. This is way too wide a range for us to build reliable applications on.
However, we at Newtuple have found a much more narrow result range at 70-90% accuracy compared to this. What is the secret sauce? It’s not just one ingredient, it's a combination of many. But the main one in this was the development of agentic frameworks
Well designed and well deployed agentic frameworks will significantly drive up the accuracy of responses from your bot instantly. Why does this happen?
Within an agentic framework developers can implement various kinds of tools to reduce the chances of errors for data questions. We can spin up an agent that runs aggregation or filter pipelines on the fly, another agent that will verify the results of a temporal query, and more. These multi-step evaluations and filters immediately push up the accuracy for temporal queries and get your application to a much narrower and predictable range.
….but we’re not getting to 100% accuracy and reliability any time soon.
Having said the above, we must be very clear about our expectations with Large Language Models used for data analysis. 100% accurate and reliable data isn’t happening anytime soon. The very nature of AI in this era is that it’s driven by probabilistic systems i.e. large language models. A probabilistic system will not be able to produce the exact same result each time you run a question on a temporal dataset. However, this isn’t a question that should deter complex applications being built on top of AI capabilities.
The key question to ask is this: How many more use cases are you able to unlock with an agentic model for data analysis? My guess is this is an exponential increase, between 10-100x more capabilities get unlocked with LLMs for data analysis compared to the existing technology that relies primarily on heuristic and deterministic based approaches to data analysis. Are you okay with a system that can answer 10 times as many questions, but with an accuracy of 80% instead of 100%?
I know what my opinion is. Maybe the answer is no for you, but the reality of the current AI wave is that we have to deal with these trade-offs for the time being.
The final conclusion
The test of time benchmark is really good to understand some of the current limitations of using LLMs especially around data analytics use cases. This is something that a lot of GenAI practitioners have intuitively known for a while now. There was always a pattern of errors occurring when trying the lazy approach of using large context windows and simply asking the model to compute the answer.
Make sure your AI application is designed and developed with a good grounding of the limitations of current gen SOTA models, or else you’re in for some nasty surprises! These models most definitely expand the capabilities of AI solutions, however it’s more important than ever today to design your applications properly, benchmark your model performance for cost and performance and more than anything else, set clear expectations on the capabilities of your application with your customers. And remember, AI cannot yet replace your data team!