Nowadays, almost everyone wants the same thing with AI: AI assistants that do it all - handling every request, connecting every system, making every decision for you. We had that dream too, until we put it into actual use in our and our client’s systems. That’s when we learned that “do‑it‑all” assistants tend to wander off course, become brittle, and quietly introduce operational risk. Real reliability comes not from one giant model with vague goals, but from a network of small, well‑defined parts working in concert.
In this article, I want to share some of the hard lessons we’ve learnt at Newtuple: assistants that worked in a dev environment but broke in the wild, architectures we had to simplify to make them supportable, and evaluation methods that helped us catch issues before users did. We’ll walk you through those lessons, showing how to go from ambitious concept to stable, production‑ready assistant.
Connect with Newtuple to explore AI Agents
Definitions
Before we go further, I wanted to clarify two terms that get used loosely: Agents and Assistants. Let’s put some definitions together.
Agent
In my eyes, an agent is an LLM call (mostly wrapped in an agentic framework), connected to a small and curated set of tools and, when needed, other agents. It owns one job with a clear input, a typed output, and a single success metric. Its autonomy is bounded by the tools and policies you give it.
Assistant
An assistant is a composition of multiple agents that together complete one identified business process. The assistant provides orchestration and shared state, sets policies and guardrails, manages memory, and coordinates handoffs. Its success is measured at the process level: goal completion, quality, latency, and cost.
Why this distinction matters
Scope: agents do one job; assistants own a whole workflow.
Evaluation: agents are tested against a contract; assistants are tested on outcomes.
Scaling: you scale by adding or refining agents and orchestration, not by inflating a single agent’s scope.
| Dimension | Agent | Assistant |
|---|---|---|
| Scope | Single task | One business process |
| Tools | 2 to 5 curated tools | Calls agent proxies; few direct tools |
| State | Local working state | Shared process state and memory |
| Output | Typed artifact (JSON or file) | Process outcome (decision, document, action) |
| Metrics | Precision, SLA, compliance | Goal completion, latency, cost |
Naming note: Some SDKs and platforms use “assistant” to mean a single configured tool‑using entity (for example, a product API object), not a multi‑agent composition. In this post, assistant always means a composition of multiple specialized agents orchestrated around one business process, and agent refers to each individual, tool‑using role with a bounded mandate.
Now, having got that out of the way, let’s get straight to our learnings from developing AI assistants:
Learning 1: Generalized assistants do not work
The idea of a single assistant that can “do it all” inside an organization is attractive. It promises fewer moving parts and a simple interface for everything. A new wave of autonomous tools promises to handle everything behind one utterance or API call. The implied pattern is a single, overarching assistant that sits in front of many disparate AI agents and services. You speak once; it plans, delegates, reconciles results, and takes action. In demos, this feels magical.
In reality, the scope balloons, the instructions blur, and the system loses its footing.
When one assistant tries to handle every request, it becomes hard to constrain, hard to evaluate, and even harder to debug. Small cracks appear first, then the answers drift, and pretty soon no one is sure which part failed or why.
A much better path today is to narrow the target. Pick one business process that you care about, describe what “done” looks like, and assemble a small team of agents that each perform a single role. The assistant owns the process, not the world. Each agent owns one job, not the entire conversation.
Why do general assistants fail?
-
Latency compounding: depth × fan‑out across agents multiplies round‑trips and costs.
-
Capability overlap: two agents can “sort of” do the same thing; the system oscillates or picks inconsistently.
-
Error amplification: a small upstream mistake snowballs as later steps treat it as truth.
-
Policy coherence: one utterance can cross domains (PII, finance, HR); keeping data residency and least‑privilege correct across hops is non‑trivial.
-
Change management: upgrading one agent silently shifts behavior elsewhere; blast radius grows with graph size.
-
Observability gaps: without hop‑by‑hop traces and typed contracts, root‑cause analysis turns into guesswork.
What to do instead?
The best way to design assistants today is to build it for specific, narrow processes that are well defined in the organization. In fact an assistant consisting of multiple agents should be developed for a very specific process.
Mental model
At a high level: the assistant owns one business process end to end; each agent inside it owns exactly one role in that process.
-
Assistant (process owner, one per workflow)
-
Holds the process map and the definition of done (DoD) for this workflow.
-
Maintains shared process state (entities, decisions, artifacts) and enforces policy/guardrails.
-
Coordinates handoffs between agents using typed inputs/outputs; tracks provenance and approvals.
-
Operates with budgets (max steps, tool‑call caps, p95 latency/cost) and clear SLOs.
-
Owns escalation paths (e.g., propose → confirm → execute) and when to involve a human.
-
Provides observability (traces, metrics, error taxonomy) and versioned rollouts.
-
-
Agent (specialist, single responsibility)
-
Has a narrow mandate: one task, one measurable outcome.
-
Accepts a typed input and returns a typed artifact (JSON/file) with provenance.
-
Uses a short tool belt (2–5 tools) with explicit policy on when/how to use each.
-
Declares preconditions (what must be true before it runs) and postconditions (what it guarantees on success).
-
Implements a failure policy (retry/backoff, fallbacks, human‑ask) and idempotency for side effects.
-
Is evaluated against a single metric (e.g., precision vs. rubric, SLA, compliance) and logs its decisions.
-
-
Handoffs and contracts
-
Every agent produces an artifact that the next step can consume without rereading the whole transcript.
-
Artifacts carry schema version, source links, and (optionally) confidence/rationale for audits.
-
The assistant/planner selects the next agent based on capability contracts, not free‑form chat.
-
Example: a Hiring Assistant
To illustrate this better, let’s take an example of a hiring assistant that we recently built which helps talent acquisition teams in different parts of the candidate search to offer process. Here’s how you can de-compose the assistants in this kind of process:
-
Profile Rating Agent: Ingests a few hundred resumes and a job description, then returns a score with a short justification and a list of missing information. Typical output: {score, justification, missing_info[]}. Metric: agreement with human reviewers and recall of red flags.
-
Interview Scheduling Agent: Finds viable slots that respect constraints for both candidate and panel, confirms the meeting, and sends reminders. Typical output: {status, proposals[], confirmed_slot?, ics_link}. Metric: time‑to‑confirm and reschedule rate.
-
Interview Rating Agent: Consumes a transcript or recording and scores competencies against the JD or a rubric. Typical output: {competency_scores{}, evidence_snippets[]}. Metric: inter‑rater reliability with the panel.
-
Recruitment Document Agent: Generates standardized documents such as offer letters, rejection notes, and JD variants, and tracks diffs against templates. Typical output: {document_url, template_name, diff_summary}. Metric: time‑to‑document and template compliance.
As you can see from the above, the hiring assistant itself consists of 4, specialized and narrow agents that are expected to perform one or two functions really well. When you frame the work this way, reliability improves quickly. Users get consistent behavior, developers get clean failure surfaces, and product teams can add capability by adding or refining agents rather than by growing a single, fragile prompt.
Learning 2: Limit tools per agent, and write task‑specific prompts
Too often, agent developers have a tendency to add as many tools as possible to every agent to preserve optionality. In our own work, we have repeatedly seen agents become erratic once the number of available tools crosses a small threshold (>10), precisely because multiple legitimate solution paths exist for the same user request. On paper, this looks like flexibility. But in production, it adds to the ambiguity. Each additional tool introduces another possible path to a result, and when several paths are equally plausible the model’s choices become unstable from run to run.
What actually goes wrong
-
Erratic behavior through optionality. As the tool list grows, there are simply more ways to solve the same request. The agent takes different routes on different days, which means outputs vary even when inputs don’t.
-
Hidden incompatibilities. Tools carry their own assumptions - sampling strategies, rate limits, pagination quirks, time zones, attribution windows. Minor differences accumulate and show up as inconsistent numbers or formats.
-
Latency and cost creep. Extra tools mean extra retries and extra round trips, especially when an agent “probes” a few options before committing. That drift is hard to spot without disciplined observability.
-
Prompt bloat and weaker evals. To explain every option you start writing encyclopedic prompts; the broader the decision space, the harder it is to write clear tests with a single notion of “correct.”
A practical tool budget
-
Three to five tools are a nice sweet spot for your agent, provided you supply a decision table, clear fallbacks, and continuous evaluation. Expect to spend time on guardrails and scenario building within your prompt.
-
More than five tools is going to be a bit of a stretch in terms of reliability. Ideally you should split this kind of agent into smaller roles, or hide the complexity behind a proxy agent that presents as a single callable tool with a tight contract.
Design the prompt for the task, not the world Generic prompts invite generic behavior. Give each agent a task‑specific prompt that names its single job, the shape of its inputs, the few tools it may use (with rules for when and when not), and the exact artifact it must return. The aim is to make the happy path obvious and the failure path explicit.
To Summarize:
-
Start with the smallest tool set that truly covers the job. Add a tool only when traces or evals reveal a specific and repeatable gap.
-
Make tool choice explicit with a decision table or a very detailed prompt that the agent reads.
-
Wrap each tool with guardrails: input validation, idempotency for side effects, and safe retries with backoff. Return typed responses so failures are clear and recoverable.
-
Log each tool call with inputs, outputs, timing, retries, and error class. Use structured logs so you can group by intent, by tool, and by failure mode.
-
Test at two layers. First, contract tests that check tool selection and output schema. Second, journey tests that cover the common flows end to end. Run both before you ship changes.
-
For analytics and reporting agents, maintain a KPI registry that binds each metric to one canonical source and query template, including timezone and attribution rules. Do not let the agent improvise these fundamentals.
Keep the tool belts tight and the prompts specific. When you remove ambiguity from the system, agents become easier to trust, easier to debug, and far cheaper to operate.
Learning 3: Be wary of agent routing
In almost every multi-agent assistant we’ve developed, one of the biggest challenges to reliable and more accurate outputs is cleaner routing. When you’re building out a multi-agent assistant, it’s quite tempting to build a multi-hop multi-agent design to cover all your use cases. A “router” hears the request, chooses the next specialist, gathers the result, and repeats until the job is done. With two or three sub‑agents this can feel crisp and even elegant. As the graph grows, though, the router turns into a bottleneck: decision rules leak into an ever‑longer prompt, small mistakes ripple from one hop to the next, and before long you’re chasing latency spikes and bugs you can’t reproduce.
Why over‑routing hurts in practice: Brittle chains arise because every hop is a state handoff; a tiny error early on becomes a large mess later. Hidden complexity creeps into the router’s prompt, where it’s hardest to test or version. With many “almost applicable” agents, the router starts to loop and thrash, burning tokens and time while the user waits. And when the router makes the wrong call, every downstream agent looks broken, which clouds debugging and blurs accountability.
A better approach: treat agents as tools: when I say agents as tools, I don’t mean yet another layer of handoffs. I mean the opposite. Here's an example of how you would do this inside Newtuple's agent development platform, Dialogtuple.
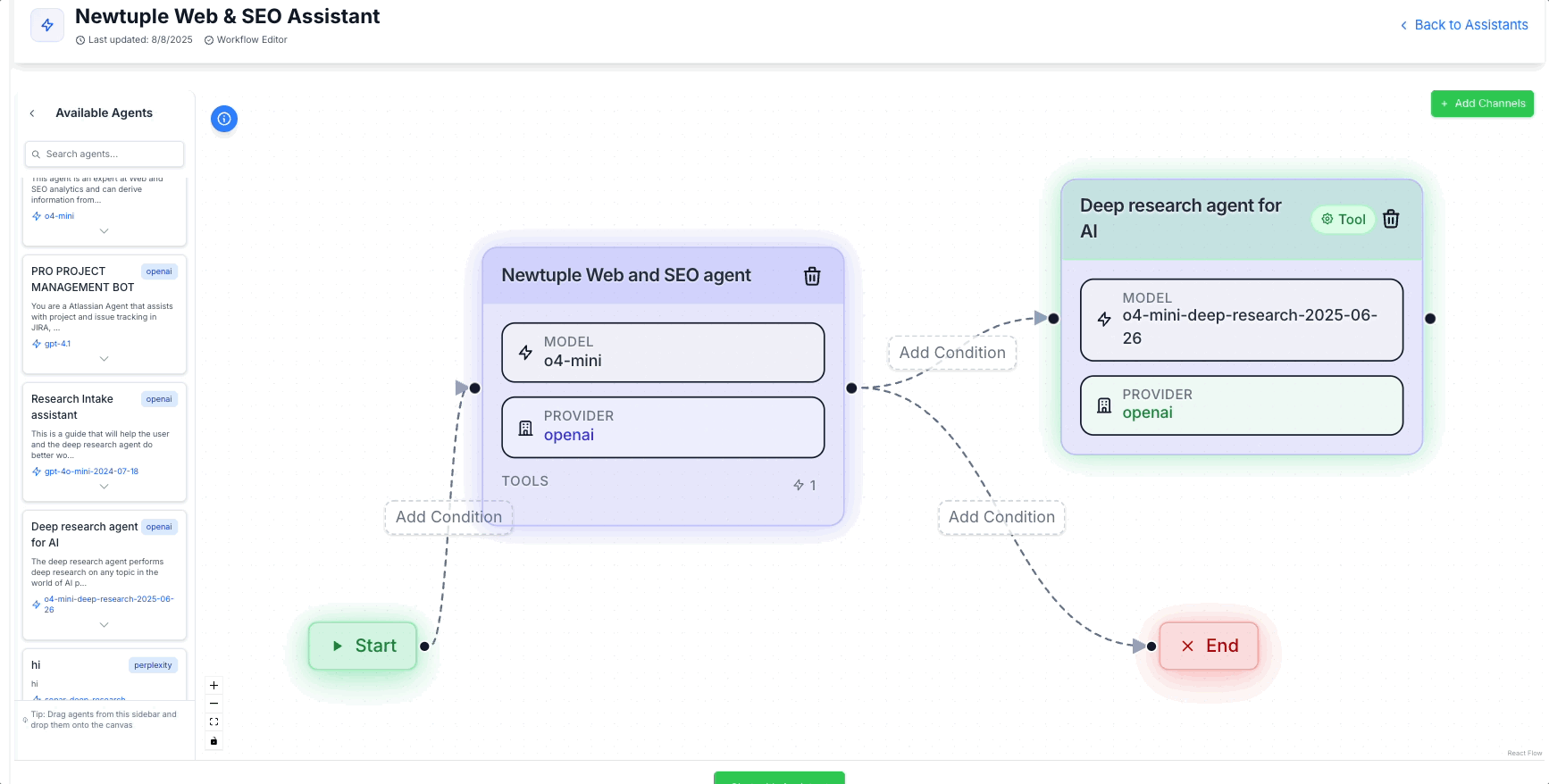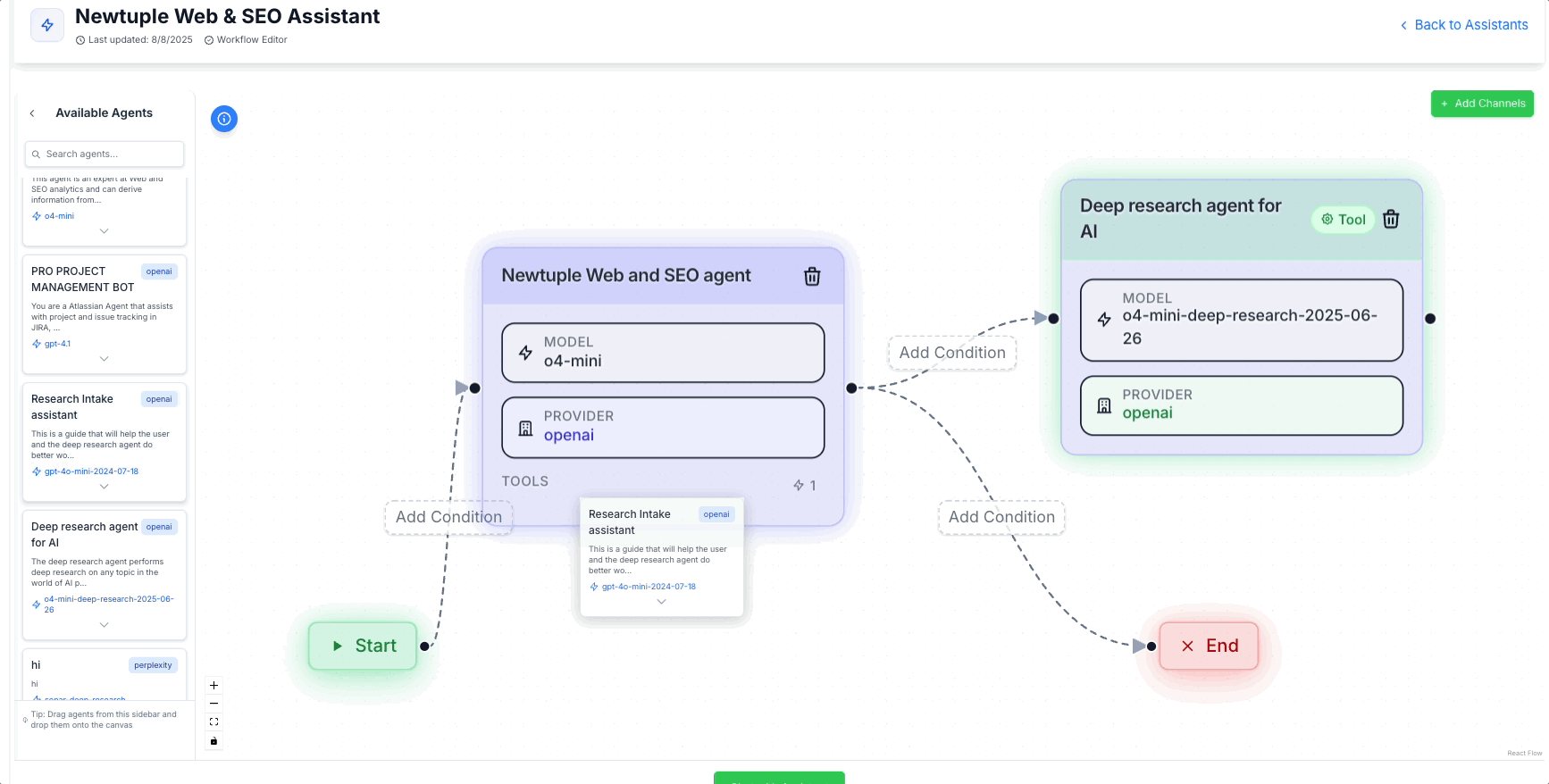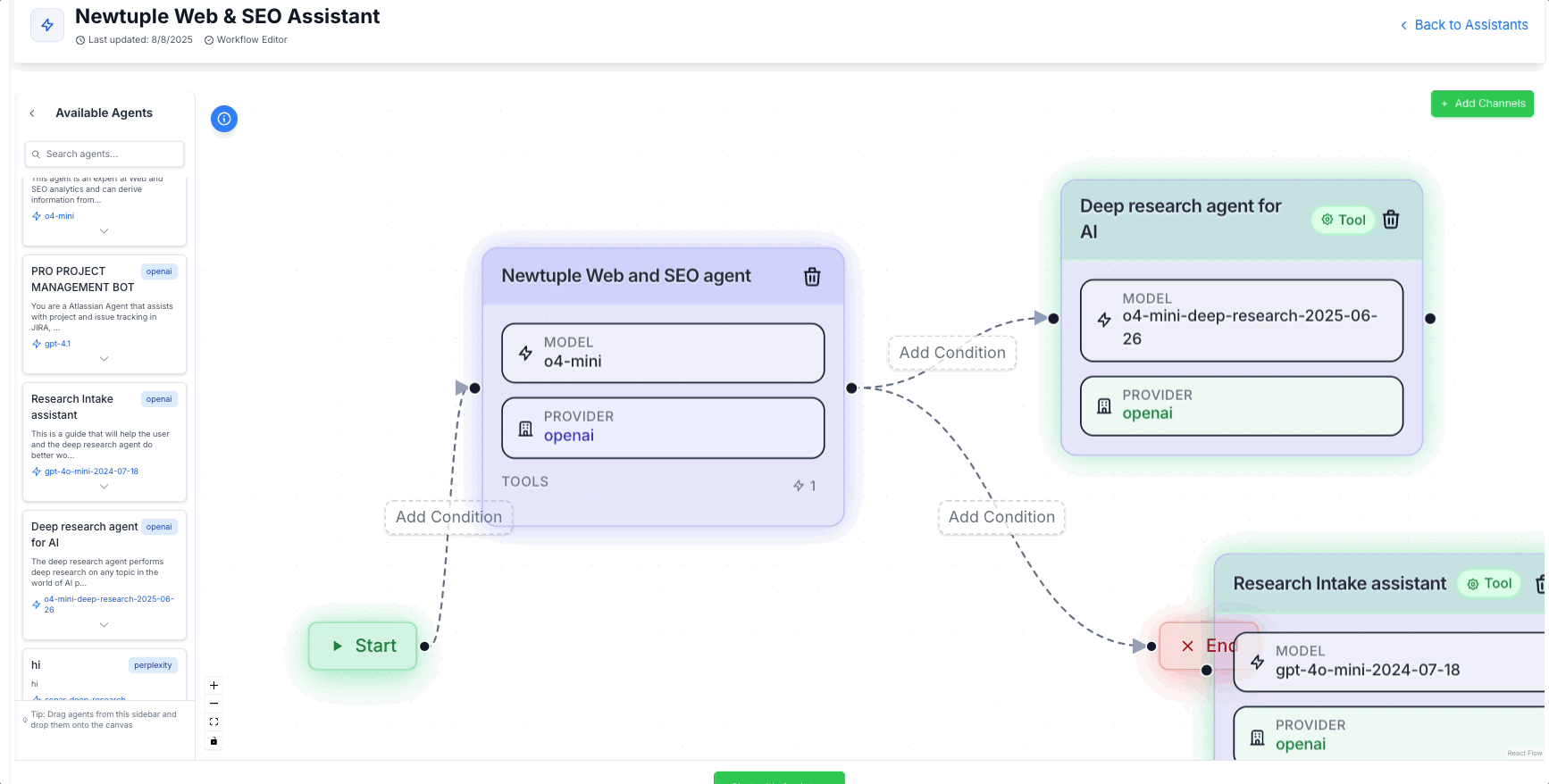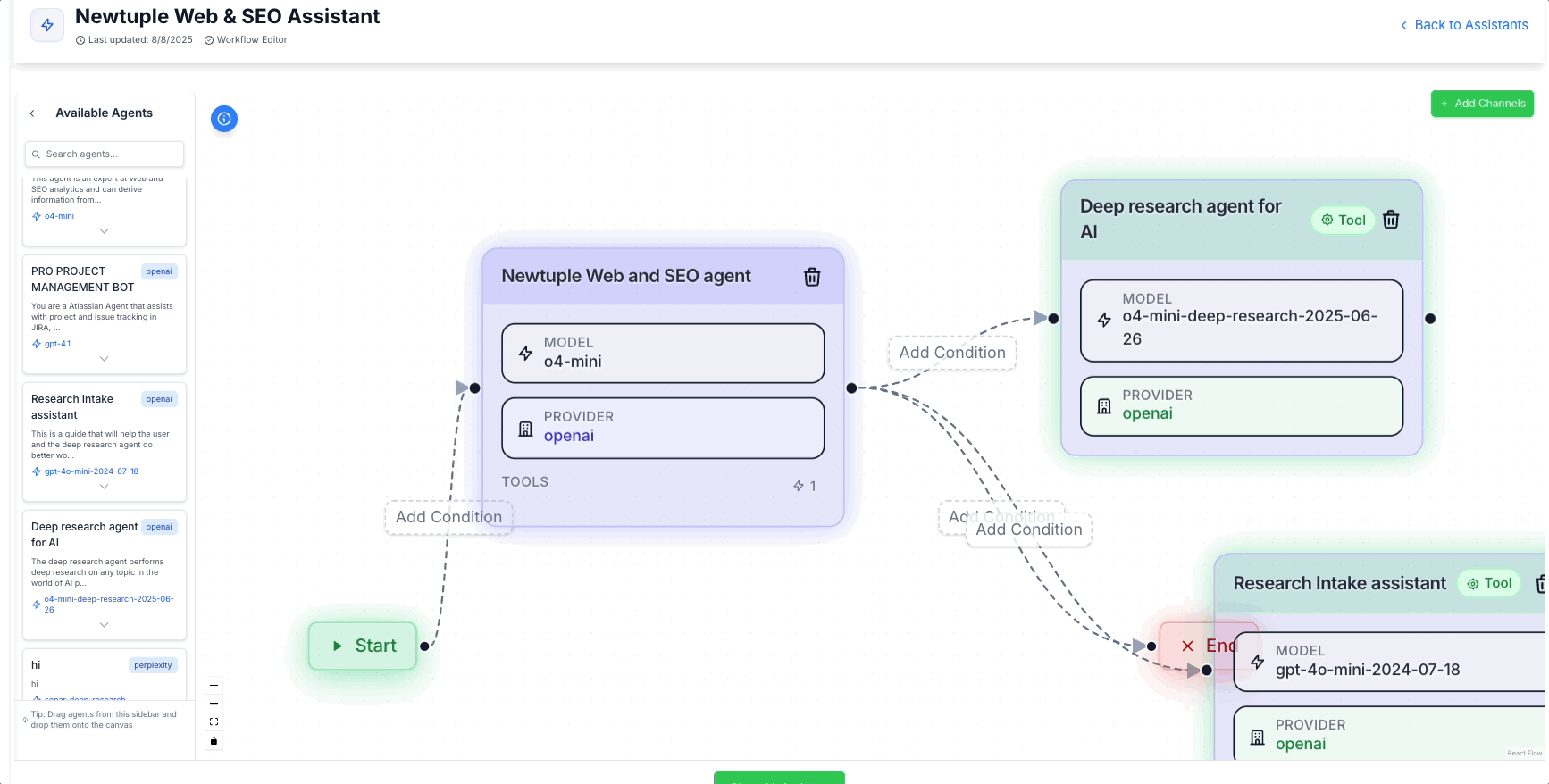 Dialogtuple's agent development platform in action
Dialogtuple's agent development platform in action
Adding "Agents as Tools" is often a better choice from a routing perspective
One primary agent keeps control of the conversation and the state, and it invokes other agents as callable tools, just like functions with typed inputs and typed outputs. Those sub‑agents do their work in isolation and return an artifact to the caller. No conversational baton‑passing. No context merges. No “who owns what state” arguments. The result is a simpler mental model: one brain holds the plan, many hands do the work.
Why this reduces breakage: Instead of shipping partial context from agent to agent (and hoping each one interprets it the same way), the primary agent sends a small, well‑typed request to a sub‑agent and receives a small, well‑typed response. The conversation history and process memory remain in one place, which means there are fewer places for drift, policy leaks, or subtle mismatches in identity and permissions. You still get specialization, but you avoid the fragile seams that handoffs create.
We built this pattern in Dialogtuple and it’s been noticeably calmer at scale. The orchestrator agent keeps the plan and state. Behind the scenes it can call profile_rate, interview_schedule, interview_rate, or doc_generate, each of which is a full agent wrapped as a tool. Those sub‑agents don’t see the whole conversation; they see only the typed request they need, do their job, and hand back a clean artifact.
What gets better day to day Planner prompts become shorter and easier to reason about, because they focus on sequencing rather than micromanaging tools. Policy and identity checks move to a visible boundary "the tool call" so it’s obvious which scopes were used and why. Traces are readable because every call has a clear input and output. And because the primary agent stays in control, you can parallelize independent calls without the router thrashing between almost‑applicable choices.
So is there a need for a “classic route”? Yes there is:
If you have a tiny, linear flow, a simple router keeps things tidy. Once the catalog grows or policies tighten, prefer the single primary agent + agents‑as‑tools model: you keep orchestration shallow, avoid context drift, and localize complexity inside the tool wrappers where it’s testable and safe to change.
Learning 4: Memory & state can make or break the application
If there’s one theme that separates a slick demo from a dependable assistant, it’s memory. Two problems show up again and again.
First, context rot: as a conversation stretches, tiny inconsistencies creep in and the assistant’s answers lose their edge - much like long engineering threads where the original intent gets diluted over days of replies.
Second, users expect learning: they naturally assume the system will remember preferences, past decisions, and the way they like things done. That expectation collides with the fundamentally stateless nature of LLM calls unless you design explicit state and long‑term memory into the framework.
Two failure modes in the wild
The ever‑growing prompt: you keep stuffing transcripts & conversation history into the next call until tokens run out or contradictions accumulate. Summaries help for a while, then drift sets in.
The amnesiac assistant: new session, blank slate. The model sounds helpful, but it forgets prior choices, repeats questions, and forces the user to manage the thread.
What works instead: Treat memory as a product surface with its own data model, not as “whatever fits into the prompt.” We’ve had the most success with a simple split:
-
Working memory (per session): a compact, structured scratchpad that captures facts, goals, assumptions, decisions, and pending actions. Summarize aggressively after important steps; store the state, not the transcript.
-
Long‑term memory (cross session): durable facts about people, policies, and artifacts - preferences, templates, canonical documents, prior outcomes. Retrieve them through typed functions (e.g., get_user_pref(timezone) or fetch_policy('leave')) rather than blind semantic search, so you always know why something was loaded.
Diving a bit more into the weeds
Episodic vs. semantic memory (in practice) The cleanest way to avoid context rot without pretending the model “remembers” is to separate what happened from what is true. Two concepts that will be helpful here are: Episodic and Semantic memory.
-
Episodic memory is the running log of this session: turns, decisions, and artifacts with timestamps. Keep it compact, summarize after each step, and prune it to what matters for the current goal.
-
Semantic memory holds durable facts that outlive any single chat: user preferences, policy documents, templates, and stable identifiers.
Store episodic details in session_state as time‑stamped events and decision summaries; keep semantic facts in profile_state or process_state with versioning and provenance. When you hydrate, bring in small, targeted slices - episodic snippets that influence the next step, and semantic facts fetched via typed getters (for example, get_user_pref('timezone')) so you can always explain why a piece of context appeared.
Graph patterns for long‑term memory For long‑term memory, a light knowledge graph beats a bag of paragraphs. Model key entities - users, jobs, candidates, documents, decisions - as nodes, and represent relationships with typed edges such as applies_to, rated_by, depends_on, and superseded_by. This makes retrieval precise and explainable: “show me everything connected to candidate C123 within 30 days in the hiring workflow” becomes a small, auditable subgraph you hydrate on demand. Attach timestamps, sources, and permissions to edges (not just nodes); prefer pointers to systems of record rather than copies; resolve conflicts with simple edge scores (recency, authority); and expire weak edges first. Assemble context by traversing the graph (e.g., candidate → interviews → scorecards → panelists), then pull documents by pointer.
Used this way, episodic/semantic layers keep day‑to‑day conversations crisp, while the graph gives you long‑term memory that’s both explainable (you can show the path to a fact) and controllable (you choose exactly which slice to hydrate for a task).
To summarize:
-
Define the state model first: what lives in session, what persists across sessions, and what stays in external systems.
-
Create typed retrieval functions for long‑term memory; avoid free‑form searches for critical data.
-
Add versioning and TTLs to working memory so context rot has a natural limit.
-
Log reads and writes with reasons; make it easy to answer “why did the assistant think this?”
-
Decide escalation early: when to ask the user, when to defer, and when to hand off to a human.
Design memory like you’d design a database schema: name the entities, define ownership, and be explicit about lifetimes. Do that, and your assistant will feel sharper in long conversations and genuinely more aware over time - without pretending the model itself remembers anything at all.
Learning 5: Evaluations are key to better AI assistants
If reliability is the goal, evaluation is the day job. Don’t try to “generally test the assistant”; This is the biggest mistake developers do when building agents. They spend all their time in developing the assistants & the agents and none of it to actually test if it works.The way to do it is as follows:
Break the flow into testable units
-
Utterance → Tool selection: given an input and minimal state, which tool (or agent‑as‑tool) should be called, with what arguments, and in what order if there’s a fallback?
-
Response format: does the agent return exactly the artifact you asked for - valid JSON, the right fields and types, no extras, and clear error states when data is missing?
-
Multi‑step conversations: across a short journey, does the assistant reach the goal with sensible sequencing, minimal back‑tracking, and correct handoffs or tool calls at each step?
Three layers of evals (and what they catch)
-
Tool‑level (contract tests): Validate preconditions, arguments, and schema of outputs. Mock outages or quota limits and check that the failure path is followed (fallbacks, partials, or a clear ask for more info).
-
Agent‑level (task tests): Given inputs and available tools, did the agent choose correctly, follow policy, and return a complete artifact? Score with rubrics where exact “ground truth” is fuzzy (e.g., resume fit).
-
Conversation‑level (journey tests): From a cold start, can the assistant complete a realistic scenario within time and call budgets, while keeping state consistent and responses well‑formed at every step?
What to measure (beyond pass/fail)
-
Correctness: exact match where possible, rubric scores where not.
-
Format compliance: strict schema validation, no stray fields, stable key naming.
-
Policy adherence: correct source/tool, allowed domains only, no private data leakage.
-
Decision quality: for utterance→tool tests, % of correct primary choices and correct fallbacks under simulated failures.
-
Behavior under stress: degrade gracefully when budgets are exceeded; never loop or call disallowed tools.
-
Cost and time targets: stay within simple step and call budgets; surface partials when targets can’t be met.
Make it concrete with small datasets Start with 20–100 process‑specific items that mirror real traffic. Include edge cases you’ve actually seen: missing fields, conflicting instructions, tool timeouts, ambiguous intents. Keep examples versioned next to the code so they evolve with the product.
Evaluations aren’t a gate you run once - they’re the feedback loop that keeps your assistant from drifting as you add features, tune prompts, and connect new tools. If you invest anywhere, invest here; it’s the difference between a polished demo and a system your team can trust day after day.
Summary
If you’re building assistants today, its good to remember the following: durability comes from clear scope, clear contracts, and clear signals. Choose one workflow that matters, compose it from a handful of focused agents, and keep orchestration thin by experimenting with different design patterns, like agents as tools. Give the system a memory you can reason about (episodic for what just happened, semantic for what remains true) and, when history needs to persist, hang those facts on a small graph so retrieval is targeted and explainable. Then test like a product team: verify tool choice, enforce schemas, and rehearse the common journeys until surprises disappear.
If this resonates and you’re staring at a hard business process, we’re happy to help.
Newtuple works with teams to scope, design, and ship assistants that hold up in production. Our agent platform, Dialogtuple underpins the approach here - typed proxies for agents‑as‑tools, clean boundaries for policy, and calmer orchestration out of the box.
If a quick sanity check, a short working example, or a lightweight demo would be useful, reach out, we’ll meet you where you are and get you to “reliable” faster. Start small, ship something testable, measure relentlessly, and let the assistant earn its breadth one process at a time.