OpenAI’s DevDay was remarkable - there were a ton of announcements across the board. Many of the announcements directly address challenges we’ve faced in development of AI applications for our clients: They’re clearly doing a great job of understanding the core requirements that software development teams are facing in building for gen-AI.
This truly feels like a transformative moment in the world of software development.
Specifically from the DevDay, for anyone who’s working at developing AI applications for their use cases, here are the most interesting ones in my opinion:
1. 128k context length and cheaper costs for GPT-4
We’ve extensively used the GPT-4-32K API in the past few months, and this is already a very smart model. We’ve used it for very complex use cases and we see very high accuracy levels. The context length was one of its only (small) limitations, especially when presented with large responses - this has now been quadrupled in size, and the API has also been made cheaper. I see this as being useful especially when there’s a complex, high value task for which we’ve been using RAG (retrieval augmented generation) flows in the past, which we could now just pass off in a larger context window.
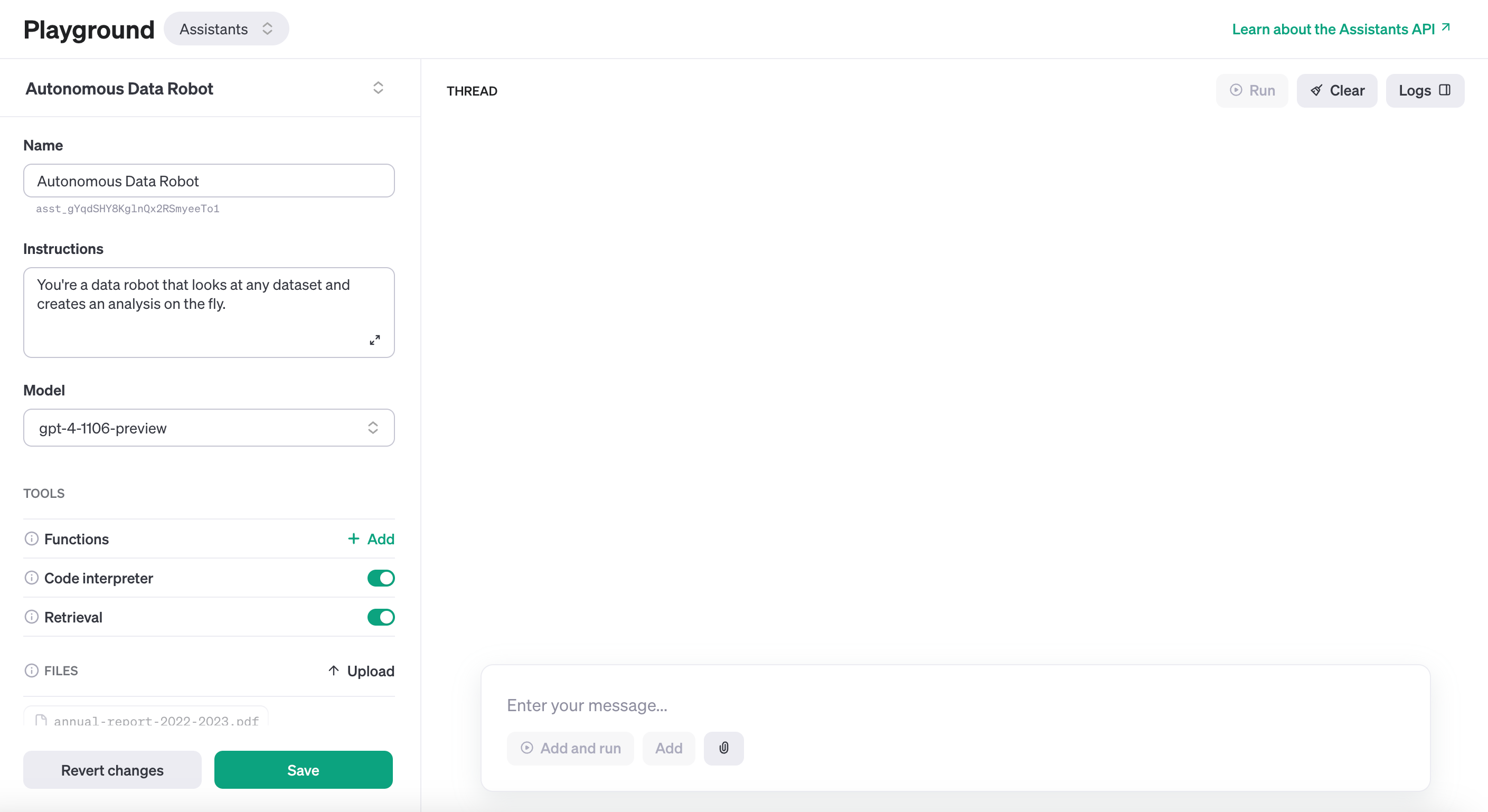
2. Assistants API to build agents in your application
This is the other brilliant release - in our AI applications we often have to build in sub modules or “sub agents” to handle particular tasks. Now the Assistants API provides us a way to easily access the code interpreter, add knowledge base references (previously done through embeddings in vector databases) and in the near future have other capabilities such as web browsing and image generation. For example, we’ve had to build specific functions to handle large data outputs in our previous cycles of application development. Now with code interpreter available “online” during an API call, we can take away this development overhead and focus on developing better business logic. We can develop smart agents within an application in perhaps 2-3x faster time than before. There's a playground for us to start developing "agents" for our applications immediately.
3. Seeds and system fingerprints for reduced hallucinations
Even with the GPT4-32K model, we’ve on occasion seen issues with hallucinations from large language models. Now, there’s new parameters in the API that help us “ground” a model with seeds and fingerprints, to make the outputs a lot more deterministic and predictable. This will immediately drive up the accuracy of generations in our AI applications.
4. JSON output mode
Another specific improvement that we’ve had to explicitly build for - in the past, we’ve had to provide few shot learning examples in our applications to produce JSON outputs as a result of an LLM call. Now OpenAI has just launched a “JSON output” which explicitly provides JSON as outputs to a request. This again helps reduce hallucinations and improves predictability of the outputs generated in our AI applications.
5. Multi-function calling
We faced this challenge with the previous version of functions when building out an AI application with multiple tools around data analysis on the fly. The previous version of functions didn’t allow us to call multiple functions in one call. Now that’s changed with the multi-function calling capabilities in OpenAI. We can run multiple tasks in parallel quite easily using the functions capabilities in OAI, as opposed to building “steps” in an AI application that run sequentially.
Summary
All of these new announcements from OpenAI improve the developer experience and help teams develop AI applications much faster than before. I'm personally quite keen to see what OpenAI's competitors come up with in response to this series of developments. Whatever their response, it's going to be a great time to "build for AI" in the next few months / years.