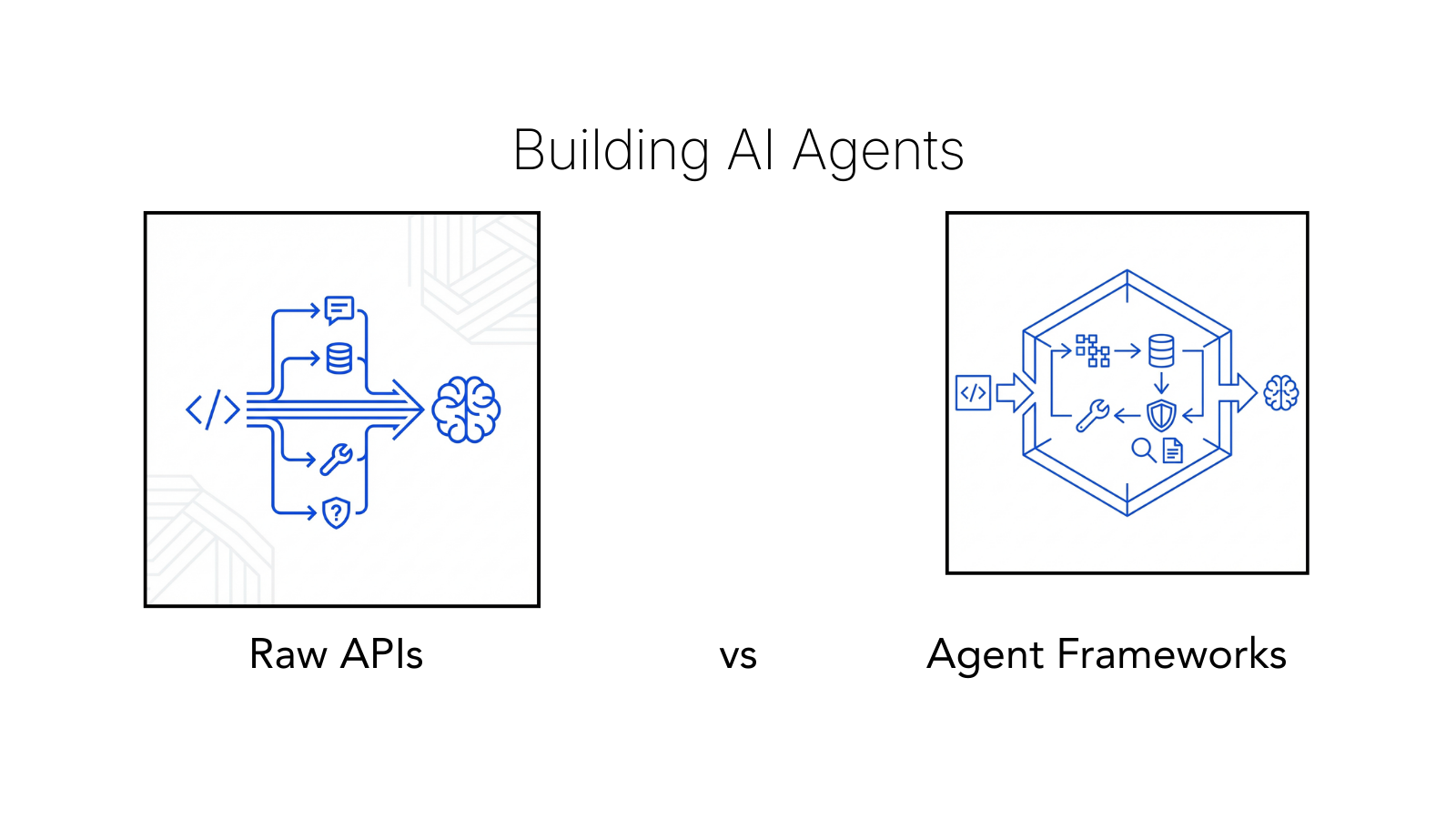
The question shows up early in every AI agent project:
Should we build directly on LLM APIs, or use a framework?
The honest answer isn’t satisfying: it depends.
But here’s the more useful answer I’ve seen emerge after watching dozens of production agent builds (and plenty of failures):
Frameworks win when it matters. Raw APIs feel like freedom until they become your ceiling.
This is also why Newtuple Technologies, after deploying agents across enterprise use cases, developed both a strong point-of-view on this choice and tooling that helps teams move from prototype to production without hitting the usual walls.
The Raw API Appeal (and Why It Vanishes..quickly)
Building directly on LLM APIs feels right at first. Your engineering team has domain knowledge, you understand your workflows. You write clean prompts, call the API, and things work.
This approach is genuinely great for three scenarios:
-
Learning the fundamentals
-
Validating a narrow proof-of-concept
-
Single-turn query systems (ask → answer)
If you’re experimenting with agent behavior, raw APIs are the fastest path to understanding. There is no framework overhead. No opinions. Just you and the model.
But the moment your agent touches production: real users, multiple turns, external tools, and memory across sessions – you discover the hidden engineering work.
Here’s the dirty secret:
The AI does maybe 30% of the work. The other 70% is tool engineering.
I have seen this pattern repeatedly across production deployments, whether it’s expense workflows, lead qualification systems, or operational assistants. The prompt is the easy part. The surrounding system is the hard part.
That “70%” looks like:
-
Designing feedback loops agents can actually parse
-
Managing state that persists reliably
-
Handling timeouts and partial failures gracefully
-
Implementing retry logic that doesn’t spiral into hallucinations
-
Logging enough detail to debug why the agent ignored a critical user instruction
None of this is in your prompt.
The Tool Engineering Problem: The Gap Between Demo and Production
The gap between demo and production is where the raw API approach breaks down. Imagine you want an agent to update a CRM record. You give the agent access to your CRM API and some documentation and it attempts to update a lead. The CRM responds with a validation error – maybe a missing field, maybe a status transition that isn’t allowed. The agent retries blindly, or worse, keeps looping.
Our analysis of production failure modes repeatedly points to this: tool interfaces designed for humans fail agents.
Agents need crystal-clear feedback.
When you design tools for agents properly, you do things like:
-
Return actionable error messages, not status codesInstead of: “422”Return: “Missing required field: first_name”
-
Truncate responses strategically and guide the next step
-
Write tool descriptions like you’re documenting for a very junior engineer who cannot improvise
-
Test tool definitions against real agent queries, not just happy-path scenarios
Raw APIs force you to rebuild this infrastructure for every project.
This is exactly why Dialogtuple, Newtuple’s agent orchestration platform, was built with native tool handling, structured responses, and failure management patterns baked in from the ground up.
Instead of reinventing tool orchestration each time, teams inherit proven patterns across deployments.
Why Frameworks Exist: Insurance Against Compounding Failure
We need to understand that a production agent needs to:
-
Remember what you said three turns ago (memory management)
-
Decide which of five tools to call (routing logic)
-
Handle tool responses, notice incompleteness, and retry correctly (retry logic)
-
Synthesize results from multiple tools into a coherent output (orchestration)
-
Log what happened so you can reproduce failures (observability)
-
Know when to give up and escalate to a human (guardrails)
Each step adds a failure point and these failures compound. Even if individual calls are “pretty good,” multi-step workflows can cascade errors. A bad assumption in step 3 feeds into step 7 and corrupts the action at step 9. Frameworks exist because production is hard. They give you the safety rails.
Orchestration
Graph-based approaches like LangGraph, OpenAI Agents SDK and ADK make workflows explicit and debuggable. You define nodes (agents/functions), edges (transitions), and conditions (branching). State becomes trackable, not implicit.
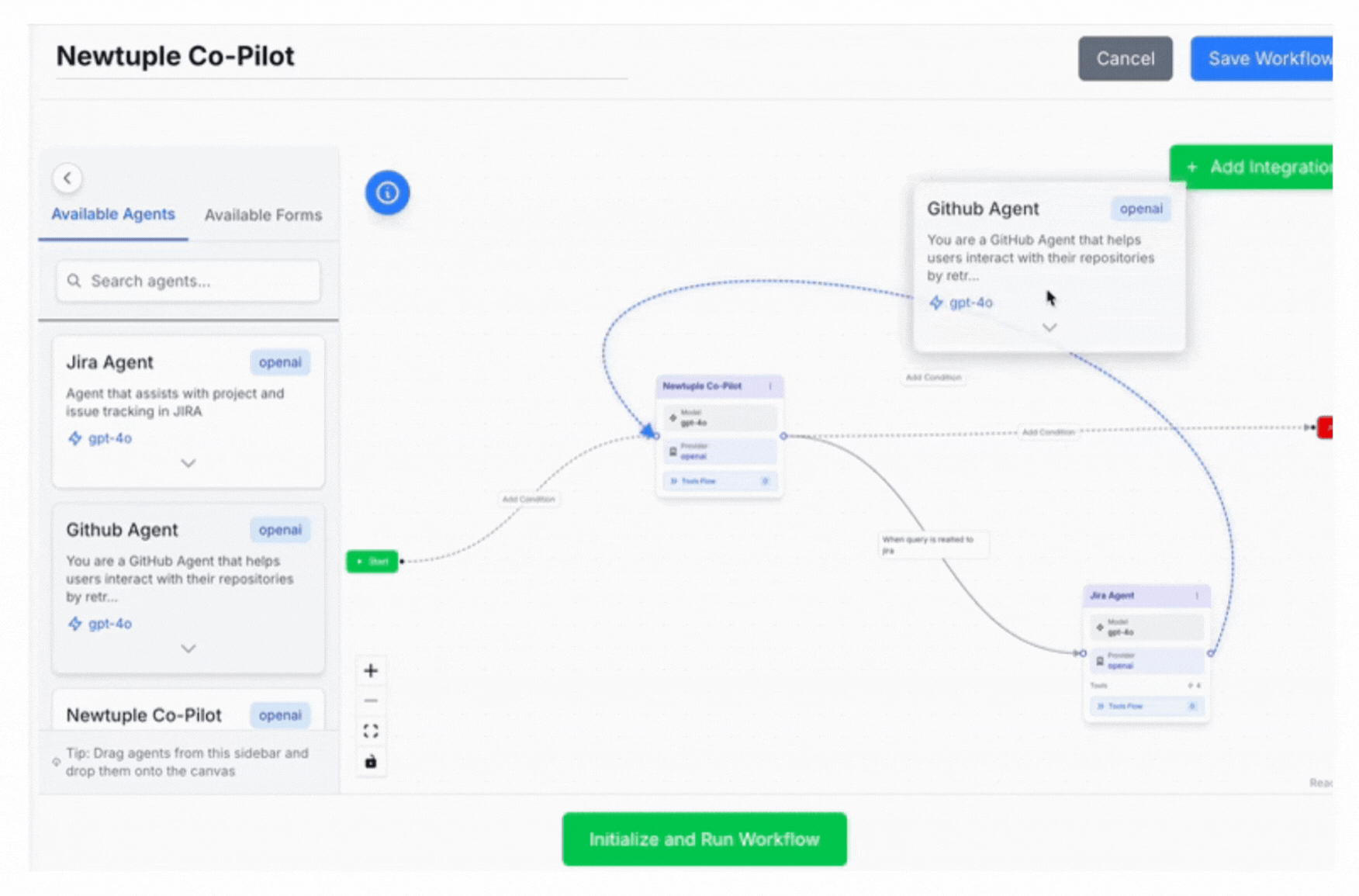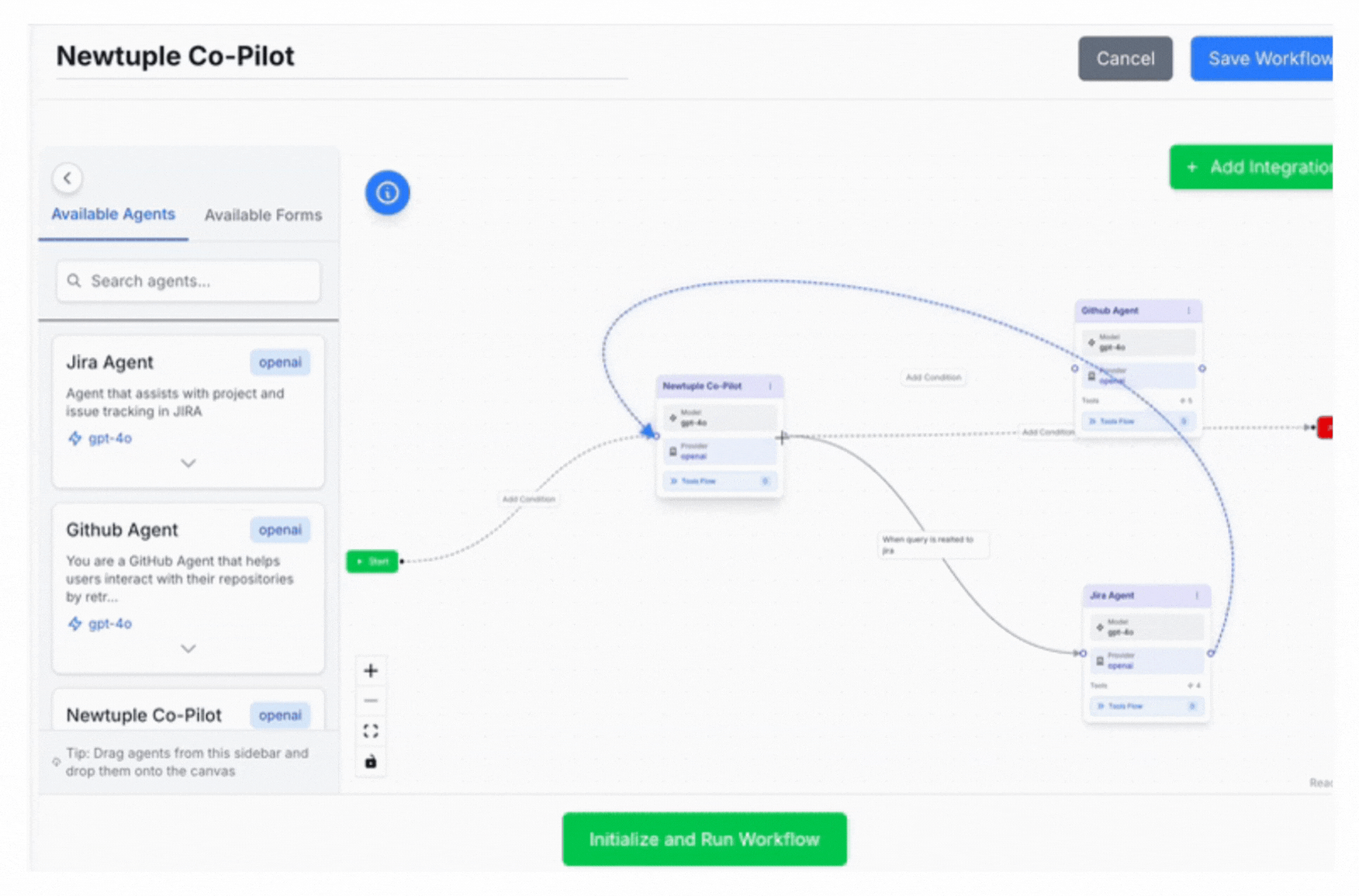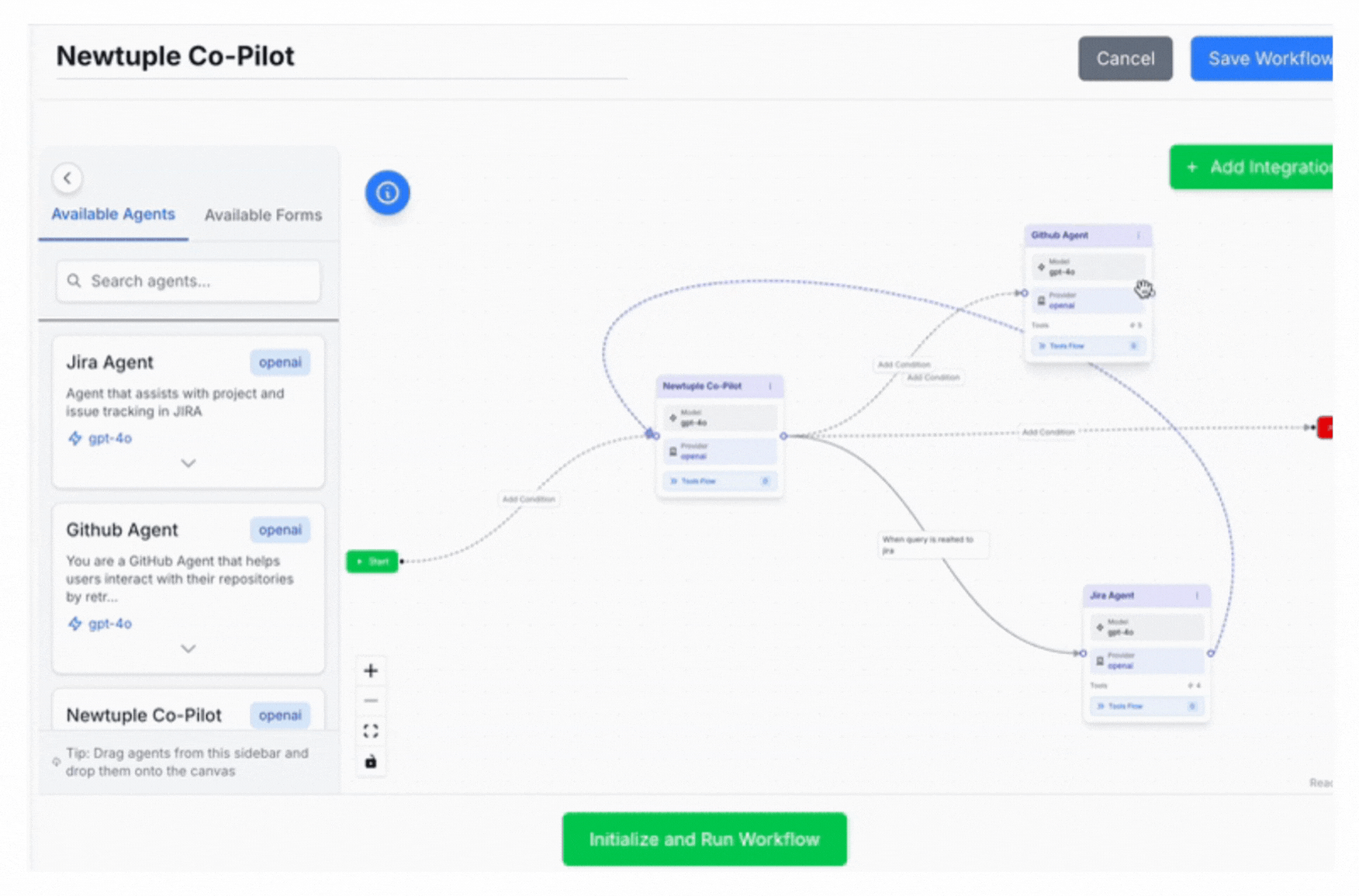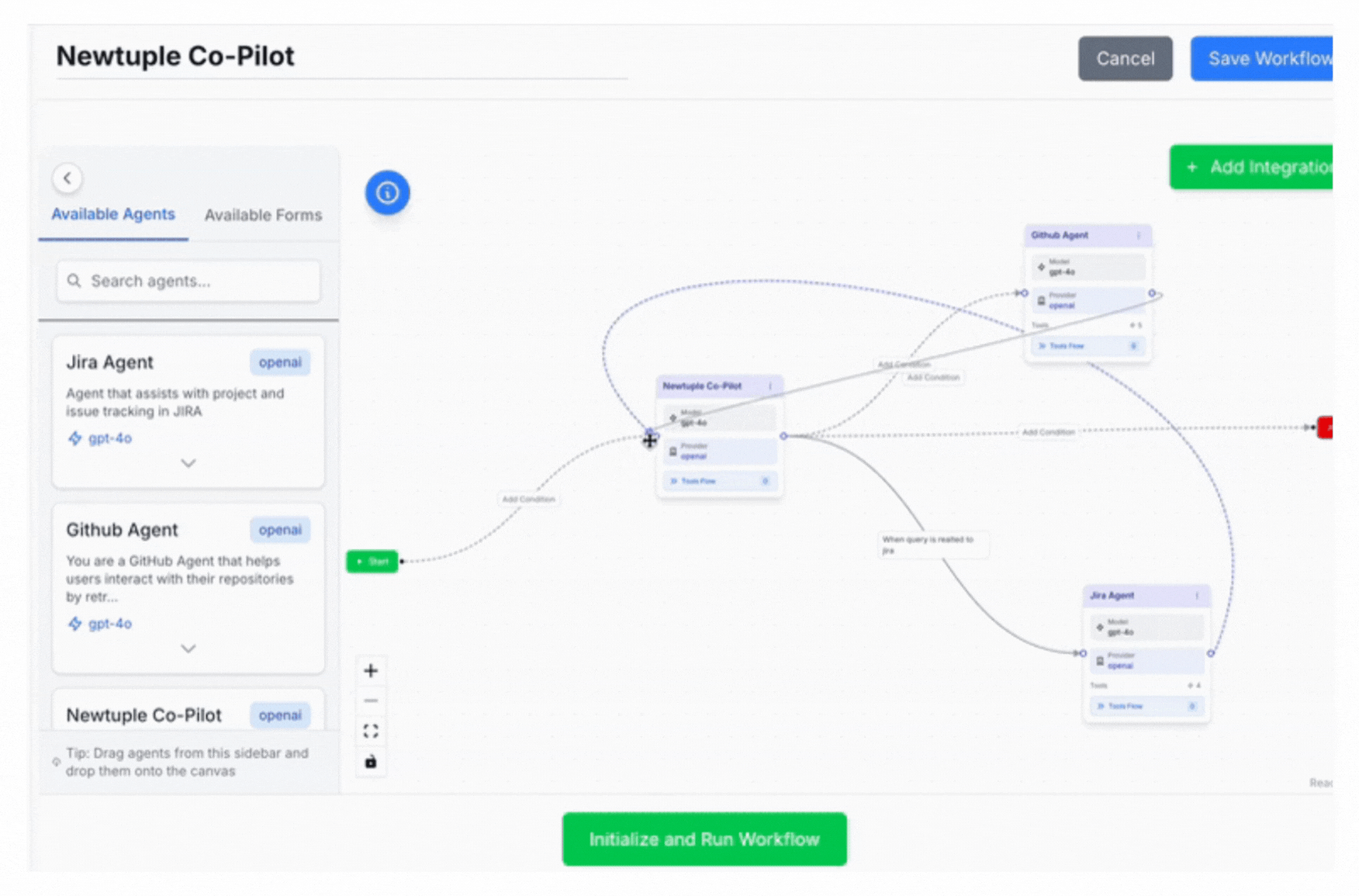
Dialogtuple builds on these orchestration principles while adding production-friendly capabilities like routing patterns and controlled escalation strategies.
Modular subagent design
One of our strongest production learnings: don’t build monolithic agents. Build specialized subagents that exchange structured data (usually JSON).
This lets you, evaluate each subagent independently, swap components based on performance and test and optimize in isolation. Here's an article that will give you more context on how to effectively build in production
Evals and observability
Agents are inherently non-deterministic. The same input can produce different outputs depending on retrieval variance, tool outcomes, or model updates. Without tracing and evaluation, failures feel random.
Rather than shipping agents and hoping they work, evals help teams:
-
Benchmark subagent performance
-
Catch regressions before production impact
-
Measure quality beyond “accuracy” (relevance, safety, formatting correctness, tool-call validity)
-
Build reliability into the development lifecycle
The Framework Ecosystem in 2025
You’re not locked into one framework. The landscape has matured, and the best teams choose based on how they want to build and operate. A practical way to think about it:
Code-first frameworks (maximum control, engineering-led)
These frameworks make use of your engineering teams to build complex agent flows, orchestration and more. This also assumes you have the necessary expertise to build on top of these opinionated agent frameworks

Low-code or code+ frameworks
Low-code agent frameworks really help bring your entire organization together, and iterate much faster. These are often based on [or piggyback off of] the code-based frameworks, but make agent building more accessible to multiple people, resulting in faster iterations and better agents.
So what's the Real Moat?
Here’s what the best teams understand:
The moat isn’t the agent. The moat is your ability to iterate.
Frameworks help you build:
-
Tight feedback loops
-
Measurable progress (via evals)
-
Safe experimentation
-
Relentless shipping cycles
That’s the difference between a flashy demo and a durable business capability.
Final Thoughts
The question “frameworks or raw APIs?” sounds like you’re choosing between two implementation styles.
In reality, you’re choosing between two strategies:
-
Build your own infrastructure (and maintain it forever)
-
Use a framework and focus on business logic and iteration loops
Every scaled agent needs memory, orchestration, tool reliability, observability, evaluation, deployment discipline, and guardrails. You can build all of this yourself on raw APIs. You’ll spend months doing it, introduce bugs, maintain it forever, and likely reinvent solutions others have already solved.
Or you can use a production-oriented framework like Dialogtuple, pair it with continuous evaluation via Gaugetuple, and focus on what actually matters:
understanding your workflow, getting feedback, and shipping every week.
The teams winning with AI agents aren’t the ones with the cleverest prompts.
They’re the ones with the best iteration loops.