Introduction
Every finance professional knows the frustration of handling large, complex PDF documents filled with intricate tables, multi-column layouts, and detailed footnotes. Manually extracting data from such documents isn’t just cumbersome it’s prone to errors.
Optical Character Recognition (OCR) frameworks promise relief by automatically converting these documents into structured data formats like Markdown or HTML. But can today’s OCR tools reliably manage challenging Wall Street PDFs without compromising critical financial data? We rigorously tested five popular OCR frameworks Docling, Dolphin, PaddleOCR, Markitdown, and Smoldocling to evaluate their capabilities.
Now days developers have a plethora of options for text extraction - starting from a number of cloud based OCR services like Azure Document Intelligence, AWS Textract, GCP's Document AI and others. In this article, we will focus on comparing Open-Source libraries that are available for document extraction.
Should we just use an LLM for document extraction?
It's also quite tempting to directly make use of an LLM for document extraction. Some of the state of the art models today are already very good at this particular task and provide a good alternative to traditional OCR services. Infact, this was the case nearly 18 months ago when we compared GPT-4V vs a prominent OCR service. Keeping this in mind, it's quite tempting to directly send your large format documents to an LLM.
However, while a multi-modal long context LLM might provide good results for direct extraction from large format documents compared to OCR services on the cloud, their accuracy is still not optimal - for sensitive industries like financial services and healthcare, there is a need for a very high accuracy (>90%), and this is where just using an LLM directly for document extraction might not be ideal.
In our extensive experience with these use cases - we find OCR libraries in combination with LLMs provide the best results for document extraction.
Let us take a deeper look into the most promsing candidates - but first understand the reasons why
Why OCR Frameworks Matter
OCR frameworks offer significant advantages for finance professionals:
-
Speed: Converting a complex financial document manually could take hours; through a pure LLM it could take multiple retries and high costs; an OCR achieves this in seconds.
-
Accuracy & Reliability: Reliable numeric data extraction is vital for compliance, audits, and detailed financial analyses.
-
Cost: Choosing the right OCR library reduces both direct cloud service expenses and indirect post-processing time. Remember, hosting an open source OCR library on your own infrastructure will allow you to run unlimited runs on your documents.
OCR libraries we evaluated:
-
Docling: Versatile library converting documents into structured Markdown. Github
-
Dolphin: Multimodal parser analyzing layouts and parsing page elements. GitHub
-
PaddleOCR: Comprehensive OCR toolkit supporting multiple languages and lightweight models. GitHub
-
Markitdown: Lightweight Python utility converting documents into structured Markdown. GitHub
-
SmolDocling: Compact OCR model designed for efficient structured data extraction. Hugging Face
Compute Requirements: Understanding the computational needs of each OCR tool is crucial for optimal deployment. Below is a summary of the minimum system requirements for the evaluated tools:
| Framework | CPU Requirement | RAM Requirement | GPU Requirement |
|---|---|---|---|
| Docling | Python 3.9+, x86_64/ARM64 | Any | Optional (for enhanced performance) |
| Dolphin | 1.5 GHz x86/x64 with SSE2 | 2 GB | DirectX 9.1+ with 128MB VRAM |
| PaddleOCR | Intel i5 or equivalent | 4 GB | Optional (CUDA 11.8+ for GPU support) |
| Markitdown | Python 3.7+ | 2 GB | Not required |
| SmolDocling | Python 3.8+, x86_64/ARM64 | 2 GB | Optional (for GPU acceleration) |
One more interesting fact on the technologies we evaluated - we are increasingly seeing the merging of traditional transformer based architectures for OCR - indicating that there is deep potential to unify visual and linguistic understanding into a single, end-to-end model that can directly parse document images into structured, semantically rich outputs without relying on separate OCR engines.
This paradigm shift is exemplified by models like Dolphin and SmolDocling:
-
Dolphin: Developed by ByteDance, Dolphin employs a two-stage "analyze-then-parse" approach. Initially, it performs comprehensive page-level layout analysis by generating a sequence of layout elements in natural reading order. Subsequently, these elements serve as anchors for parallel content parsing using task-specific prompts on a language model. This architecture allows Dolphin to handle complex document structures efficiently, integrating visual and textual information seamlessly
-
SmolDocling: A collaborative effort between IBM Research and Hugging Face, SmolDocling is a compact vision-language model with 256 million parameters. It processes entire pages to generate "DocTags," a universal markup format that captures content, structure, and spatial layout. By combining OCR, layout segmentation, and content understanding into a single model, SmolDocling exemplifies the integration of visual and linguistic processing in document analysis.
These models demonstrate the potential of transformer architectures to streamline document processing by integrating visual and textual analysis, leading to more efficient and accurate understanding of complex documents.
How We Conducted the Tests
For this evaluation, we specifically selected pages from 10 public financial documents, targeting only those sections most likely to challenge OCR frameworks pages dense with complex tables and mixed text layouts. This focused selection provided a robust challenge rather than using entire reports. Each OCR framework was tested using these difficult samples, assessing their performance based on:
Table reconstruction
-
Numeric precision
-
Heading hierarchy accuracy
-
List and data integrity
Scoring Criteria:
-
High: ≥80% accuracy
-
Medium: 60%-79% accuracy
-
Low: <60% accuracy
Detailed Findings
OCR Framework Scorecard
| Framework | High | Medium | Low | Overall Grade | Typical Issue |
|---|---|---|---|---|---|
| Docling | 2 | 6 | 2 | B+ | Merged-cell tables split |
| Dolphin* | 0 | 6 | 3 | C+ | HTML colspan confusion |
| PaddleOCR | 0 | 6 | 4 | C | Space-aligned table drift |
| Smoldocling** | 0 | 5 | 5 | C- | Silent page skips |
| Markitdown | 0 | 4 | 4 | D | Flat text, no structured tables |
*One Dolphin test crashed on a 300-page document and was not included in scoring.
**Smoldocling output looks good but it skips pages while processing multipage pdf
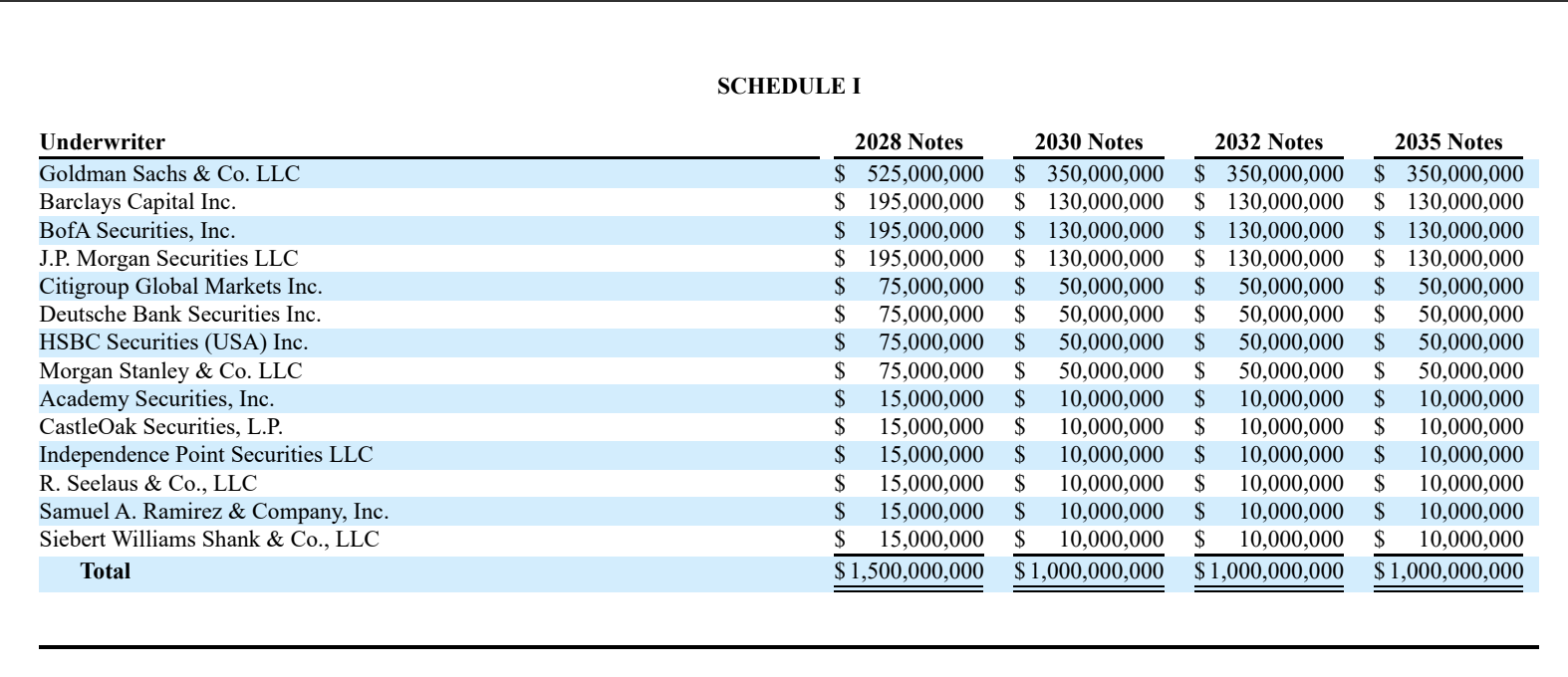
In-depth Case Study: Apple’s Underwriting Schedule
Below is one of the actual pdf screenshot "underwriting table" from Apple SEC filling document FORM 8-K May 5 , 2025 used for our detailed case study , we will be using this as "ground truth":
OCR Outputs Visual Comparison:
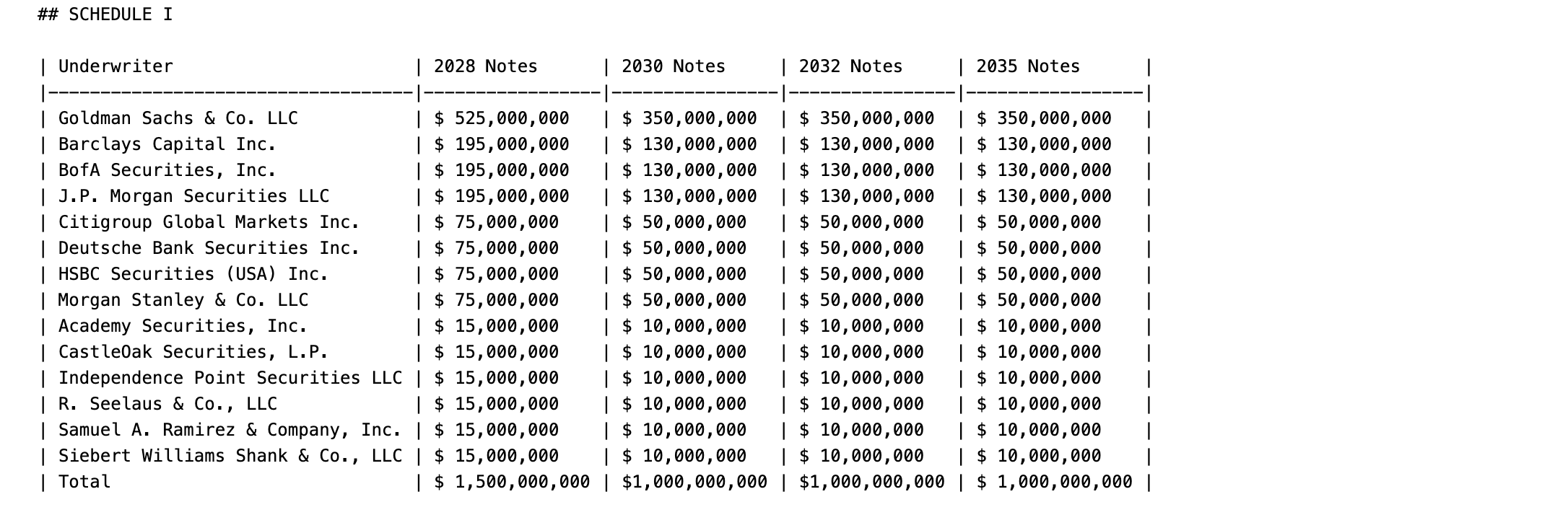
Docling Output:
- Precise structured Markdown tables requiring minimal corrections.
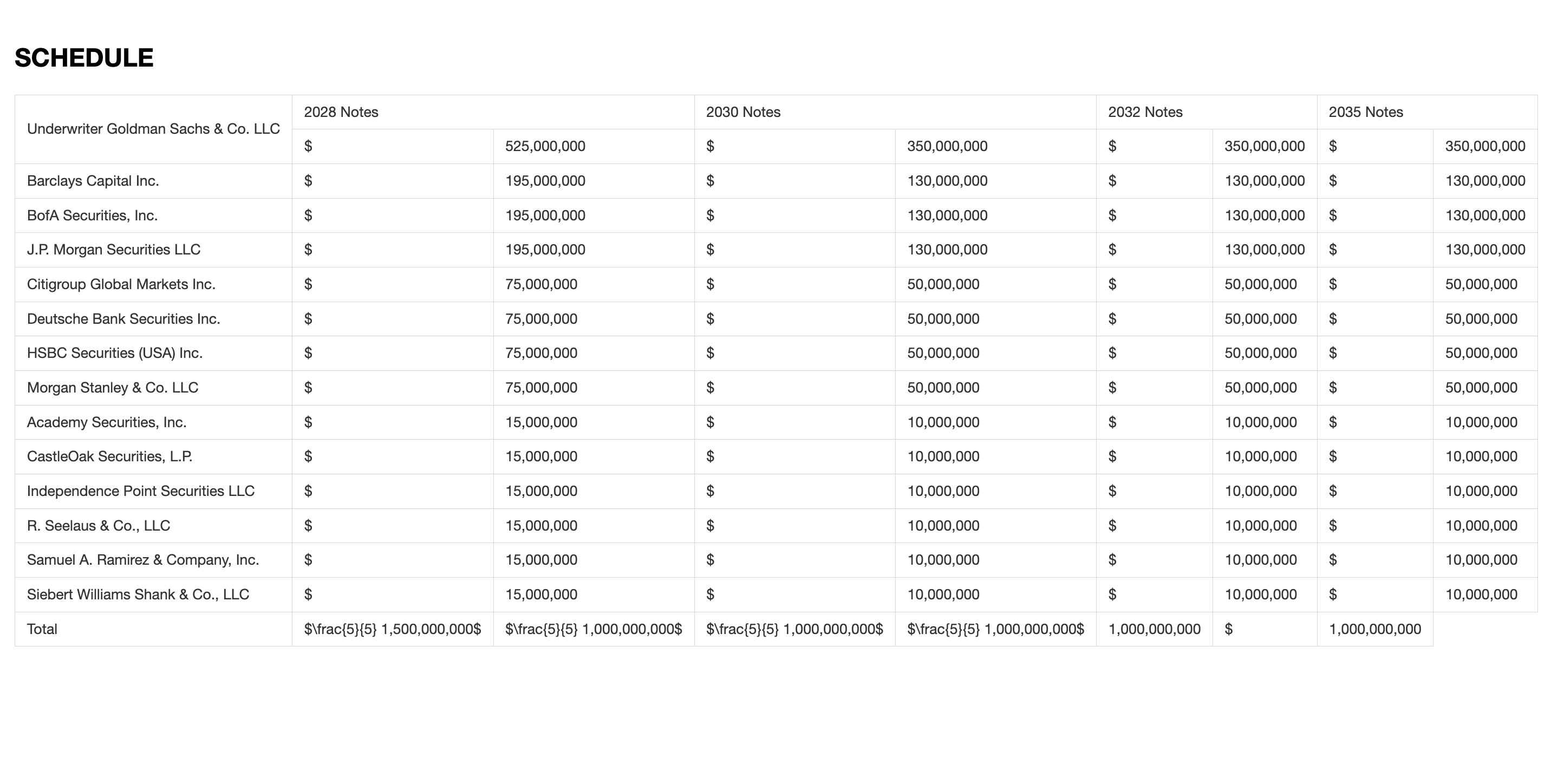
Dolphin Output:
- Good HTML structure but struggles with complex merged cells.
PaddleOCR Output:
- Quick text extraction but misalignments and numeric inaccuracies.

Markitdown Output:
- Fast extraction but outputs unstructured, flat text.

Smoldocling Output:
- Good visual output, but inconsistent due to skipped pages.

Recommendations for Practical Use:
-
Docling: Recommended for precise structured Markdown tables with minor corrections.
-
Dolphin: Suitable for HTML pipelines, effective for simpler structured layouts.
-
PaddleOCR/Markitdown: Best for raw text extraction where speed is prioritized over structure.
-
Smoldocling: Has potential but currently unreliable due to instability and page skipping issues.
Conclusion
Despite significant advancements in OCR technology, complex financial documents remain challenging. Among the libraries evaluated, Docling stands out for its balance between structured output and accuracy. However, no OCR library delivers perfection without some post-processing.
So how can we tackle extraction of data from complex documents today? Here are some guidelines:
-
Multi-Agent Frameworks: The approach of converting documents to Markdown is integral to agentic frameworks. This method facilitates seamless integration with Large Language Models (LLMs) for tasks such as summarization, entity extraction, and question answering. By structuring data effectively, these frameworks enhance the efficiency and accuracy of downstream processing.
-
Scalability Considerations: When deploying any of these OCR libraries at scale, it's essential to consider their performance and resource utilisation. Tools like PaddleOCR and SmolDocling are designed for high-throughput environments, offering efficient processing for large volumes of documents. Docling also supports scalable deployment, especially when integrated into multi-agent systems.
-
Cost Considerations: At high scale, costs start to really matter. If you were to use a traditional OCR service, the costs are typically going to be based on number of pages or number of extractions. Self hosting an OCR library on the other hand, has considerations around the infrastructure as well as the overall technical complexity [which means more technical expertise is required to deploy these libraries]
Selecting the appropriate OCR library depends on specific project requirements, including document complexity, volume, and available computational resources. Implementing robust post-processing validation such as total checks and missing-page detection is crucial for ensuring the integrity of extracted data.
Happy parsing!