We at Newtuple build applications which leverage LLMs (Large language models) like OpenAI, Gemini etc which has become an exciting frontier for developers. Often we have to run bulk jobs which require multiple LLM calls iteratively. Some of the examples of these are:
-
Running an LLM model against hundreds of documents with a multi-step approach which includes entity extraction, saving to a database, versioning and ranking.
-
Use cases where we need to evaluate multiple news sources across different dimensions for e.g. supplier risk assessment by country & region. A bulk job would be required here to identify, prioritize and summarize multiple news data sources in one go.
-
Benchmarking using LLMs where one can provide different kinds of text input, obtain the results and compare the input/output across all the available data by either performing some kinds of aggregation on the data or making some dashboards out of it, that can give a full picture of the responses so obtained from LLMs.
Running batch jobs on top of Large Language Models is one of the fast emerging use cases in GenAI apps. Batch jobs could be used for creating benchmarks, pre-training a system, AI powered data ingestion for a large number of files, or running multiple inference calls for a client.
While the infrastructure for batch runs in LLMs is quite readily available, there are also considerations to be thought of for your application backend. Some of these are:
-
How can you sequence your generations?
-
How can you replay some or all of your bulk upload efficiently?
-
How can you rollback changes to your document repository that is populated by an LLM partially or fully?
-
How can you efficiently audit and improve your prompt-response pairs when we are talking about hundreds or even thousands of documents being processed together?
The answer is in using Pub/Sub based architectures for your backend.
We can make use of traditional pub / sub architectures to solve a lot of problems with bulk upload / bulk inferences on LLMs today. Even though this technology has been around for a while, with new GenAI applications, there are many more reasons to make use of this tech for better / reliable backend performance. Let's take a quick look at what a Pub/Sub architecture looks like:
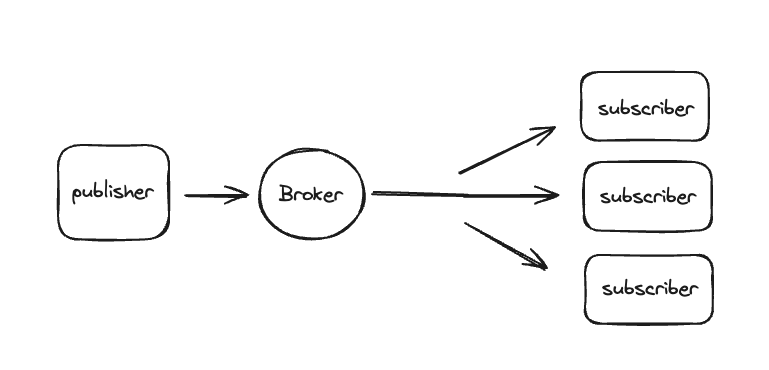 A publisher/subscriber architecture
A publisher/subscriber architecture
Pub/sub overview
The idea here behind Pub/Sub system that manages a queue is as follows:
-
It maintains a queue of messages
-
A publisher pushes messages(input) to the queue under a topic namespace
-
A subscriber subscribes to a one or more topic & all subscribers receives it whenever a message is published to that particular topic
-
Once the messages/inputs are received, those can be sent directly to an LLM for processing and obtain an output that gets stored inside a SQL or NOSQL database
One of the core strategies for efficiently managing batch jobs with LLMs is leveraging a pub/sub architecture. This system offers numerous benefits:
-
Decoupling of Application Logic: Allows decoupling of the main logic/flow of the application while maintaining the robustness of the overall system.
-
Automatic Failure Management: The failed messages in the queue are sent back to the queue on the front to be processed again, goes on until reaches max delivery threshold & finally sending to dead letter for later inspection.
-
Scalability and Efficiency: Billions of messages can queued and number of subscribers can be deployed to process incoming messages as they arrive which results in decreased turn around time that too on the same infra which also allow horizontal scaling and is cheaper.
-
Ease of Integration: With minimal effort, pub/sub services can be integrated into existing applications using provider SDKs, such as those offered by Kafka, GCP Pub/Sub, or Azure Service Bus.
Demonstration:
We can use any queue services like Kafka, GCP pub/sub , Azure service bus, AWS SQS or SNS etc. Let’s see how we can do this with Azure. Let’s dive into how you can implement this with Azure Service Bus:
-
In order to create a service bus & create publisher/ subscriber follow this article on how to create & use pub/sub service on azure
-
Once that is done we can modify the subscriber to process the message in the following manner
-
Add a [YOUR_USECASE] function
Now the flow should look like this for subscriber, while publisher keeps sending new inputs to the queue
And voilà, now you have the following things
-
A message/input publishing service that keeps publishing
-
A message/input receiver service that receives and your custom processing using LLM i.e doing benchmarking, extract entities etc , saves the responses to a database & perform aggregation & visualisation
Once the system is in place, the real magic begins:
Once the content to generation pipeline is built, this can potentially be integrated with the data engineering pipeline which can feed into data modelling, visualisation etc.
Below is an example use case of how one might use pub-sub for supplier risk assessment & benchmarking etc
-
Metrics Analysis: For every dimension of the risk, identify the risk scores and derive the keywords for qualitative analysis and convert them into structured data that the procurement managers can use or use benchmarking on various texts for entity extraction & aggregate the results by modelling it using tools like dbt.
-
Data Visualisation: Perform ad-hoc analysis and present in in using some dash-boarding tool like Apache superset to the procurement managers, discover new trends.
-
Advanced Data Aggregation: Utilise platforms like MongoDB for robust aggregation pipelines or Elastic search for enhanced text search and result normalisation.
Conclusion:
There are already tools available for batch uploads inside LLMs today. However, it makes a lot of sense to design a pub/sub architecture for your backend for better, fine-grained control over the behaviour of your app.
Implementing batch processing with LLMs using a pub/sub architecture not only streamlines operations but also opens up new avenues for data handling and analysis, propelling your applications to new heights of efficiency and insight. Whether you’re refining AI models or ingesting vast datasets, the integration of these technologies offers a robust solution to the complexities of modern data processing.
References:
https://www.elastic.co/guide/index.html
https://docs.getdbt.com/guides
https://github.com/openai/openai-python
Tags: