Amazon recently launched "Q" at its flagship event AWS re:Invent. First off, the choice of name is interesting as there's been all sorts of speculation around OpenAI and Q* and the rumours around there being some sort of AGI on the horizon. Was "Q" the original name for the AWS service or was it just re-branded quirkily to take advantage of the rumour mills? We don't know for sure.
In any case, Q is the latest in a series of GenAI announcements that have picked up pace from all the major players in the world of cloud / software / data. There's an announcement of a new AI tool almost every day now days, and AWS doesn't want to be left behind. I spent some time to try out Amazon Q, and you can skip straight to the setup section, or my summary of Q's capabilities if you wish.
So what exactly is Q? And what's going on behind the scenes?
In my early experiments with Q, it seems quite clear that this is a managed service for a retrieval augmented generation based AI bot. For those not familiar with these terminology, it's essentially an AI bot that can answer questions against your own data sources. To summarize:
Amazon Q provides a fully managed service for an organization to connect to its own data sources and run an AI bot against these data sources
What Amazon has done here is to neatly package all the components of building an RAG application inside a single AWS service. The single service takes care of connecting to multiple data sources, creating different applications, applying IAM rules, and deploying the application with a neat UI out of the box, which resembles ChatGPT.
Similar services or variants of these have been launched by Google Vertex AI search and Azure AI search.
Behind the scenes
Amazon Q is leveraging multiple other services behind the scenes to provide the "one stop to GenAI" experience to us. Here's what I've been able to glean so far:
-
Searching & Indexing is being done through AWS Kendra. Think of this as the drop-in replacement for the vector store in other RAG applications.
-
Orchestration is done with the help of Lambda functions
-
Authorization, role based access etc is managed by IAM
-
Credentials are managed inside AWS Secrets Manager
-
Logging is done in CloudWatch
-
GenAI? Pretty sure it's using a hosted model on Bedrock, just not sure what's the base model. I suppose this will also be customizable in the future
-
User Authentication is probably done behind Cognito (but I'm not sure about this)
As you can see, this offering is built on top of a number of AWS services which makes it a good fit for organizations that are already deeply embedded into the AWS ecosystem.
Setting up my first Amazon Q application
Here's a quick guide for setting up a Q application
1.Navigate to Amazon Q and click on “Get Started”
2. Click on Create Application
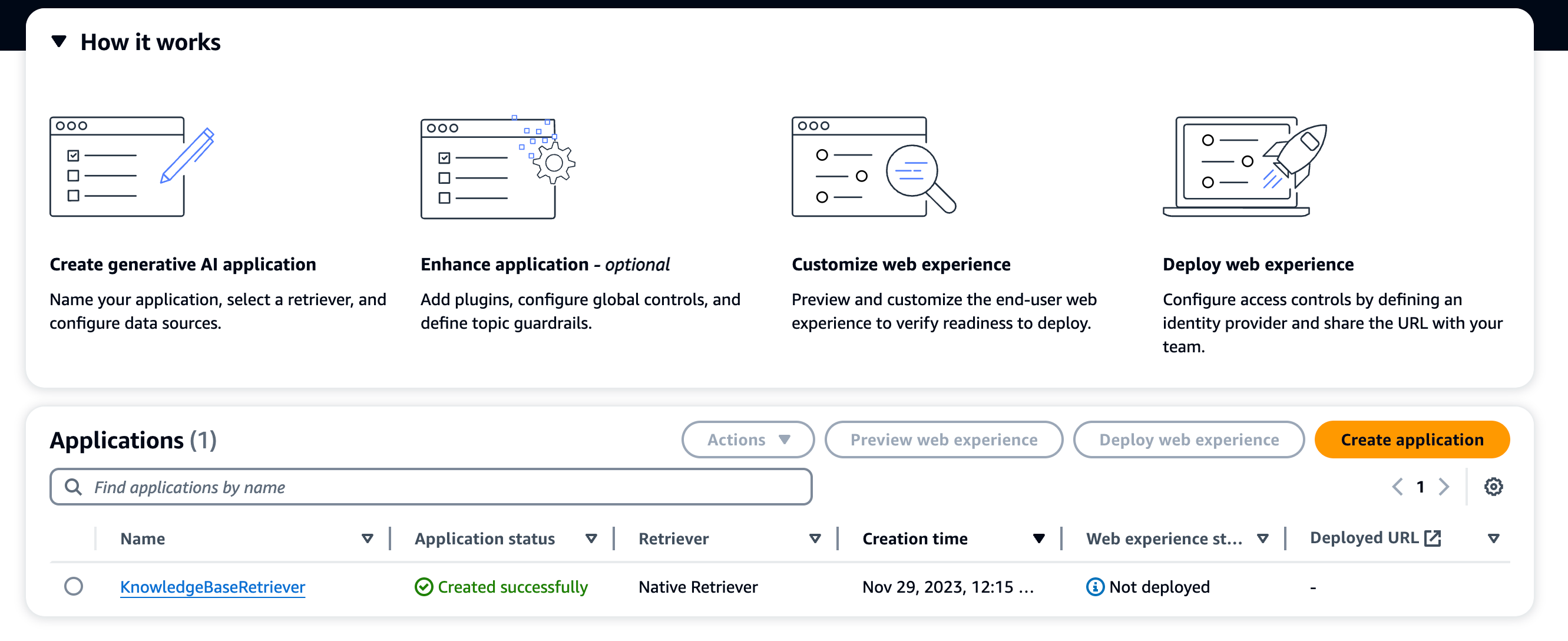
3. There’s an application quick start that allows you to add details about the application, service roles and others - authorization is built in, integrated with the service roles concept within AWS
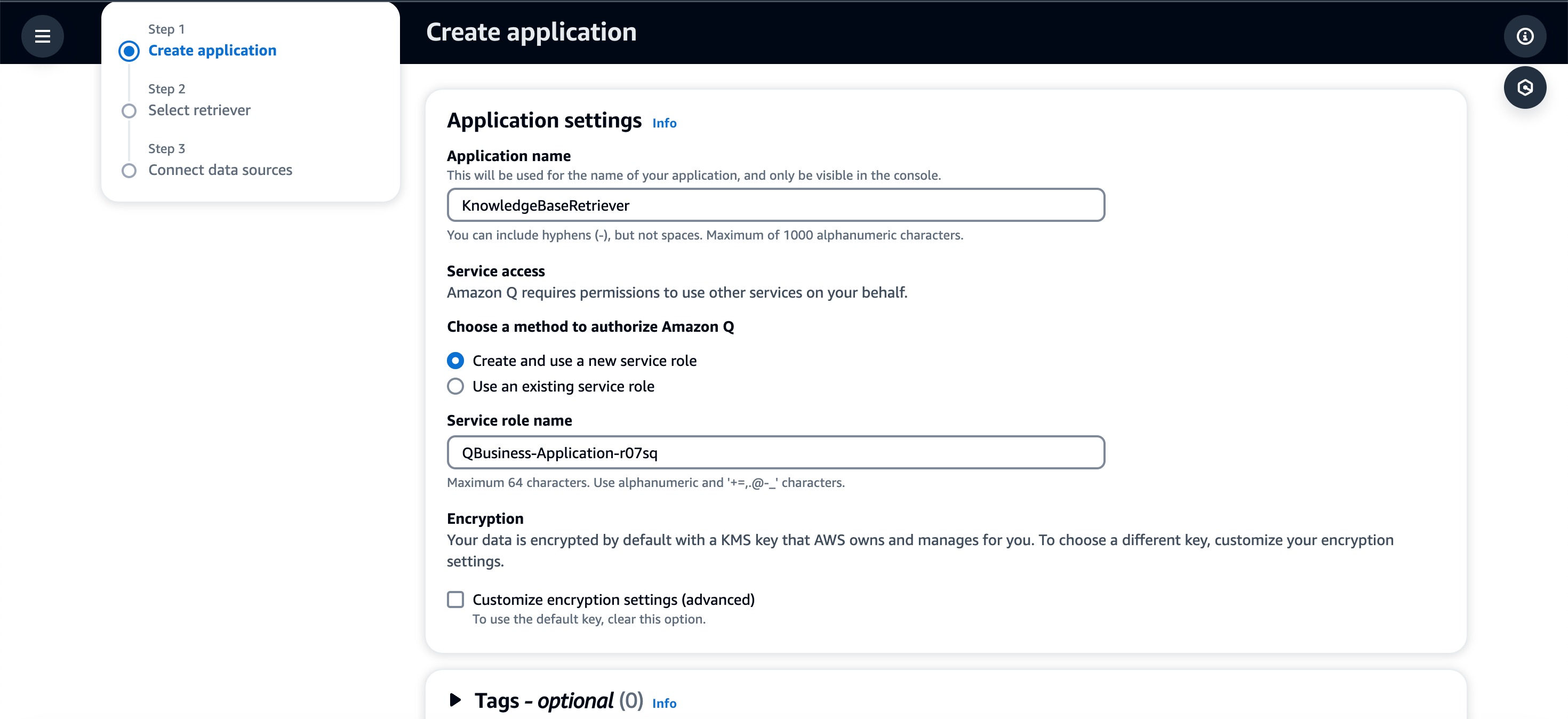
4. Next, we have to setup our “retrievers” or data sources. Looks like they’ve built in RAG capabilities into the application from within the UI. The application is based on Lambda functions + Kendra (their own version of vector DB) + custom IAM
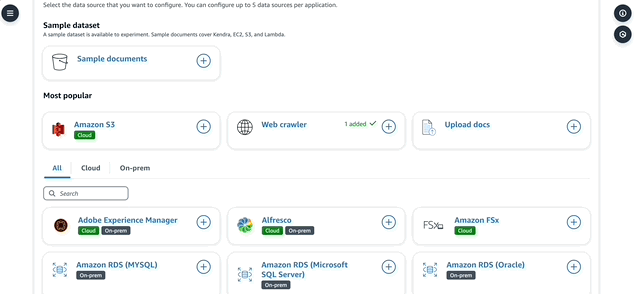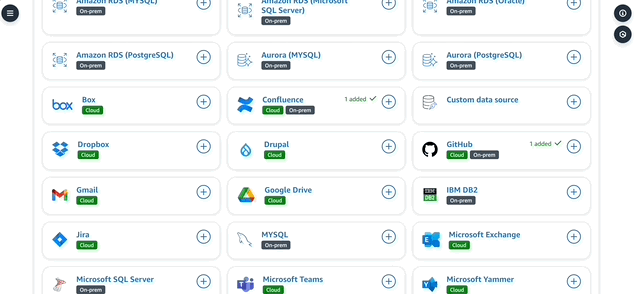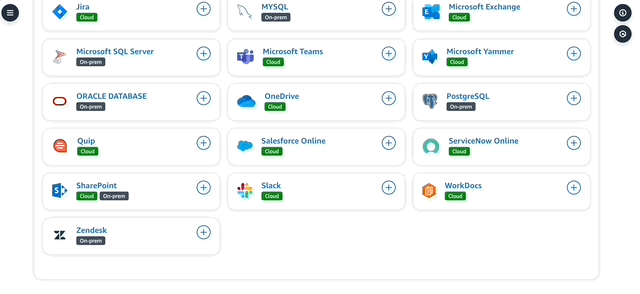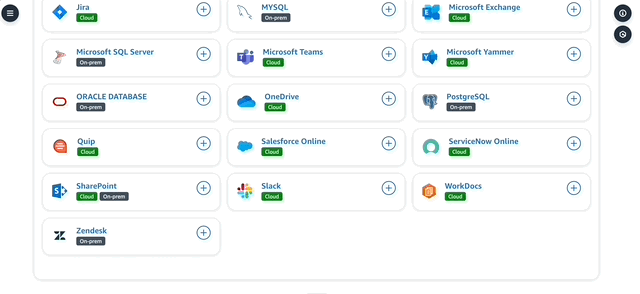
5. There are a number of data sources that you can connect to immediately in Q.
6. While setting up a data source, you can define various items like authentication (in secrets manager) and custom metadata based on the type of retriever that’s developed. There's also an interesting "Web Crawler" data source - which can crawl specific websites and URLs for information. I was able to also create this custom web crawler in Q by specifying some URLs. Q does a good job in indexing a bunch of documents it finds in those URLs - especially great if you're looking to develop use cases around competitive intelligence for example
7. And on the Postgres connector, you have to define everything about the database you’re connecting to (not great UX!). There’s a lot of scope for improving data connectivity here, I shouldn't have to define everything about the data model before the source becomes operational!
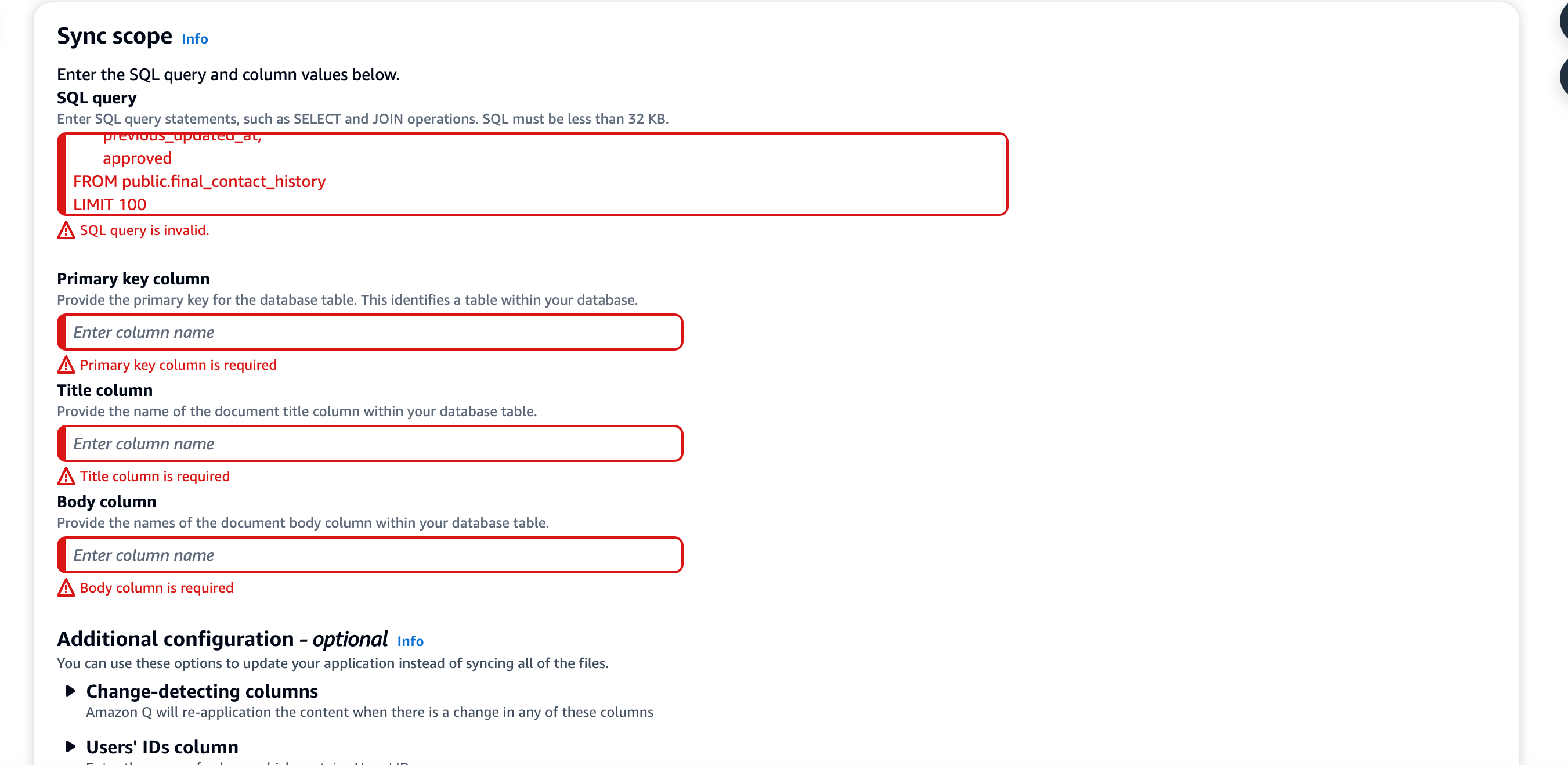
8. Once your data sources are setup, just sync and wait for it to work. This also takes a long time today! There's some scope for optimizations here, I suspect right now the underlying Kendra service is doing a ton of ingress and egress to index and crawl through the content.
9. Once synced, you can preview your bot by using the out of the box web experience. Comes pre-packaged with file upload functionality, conversation history etc. Essentially your own version of “ChatGPT” with your own data.
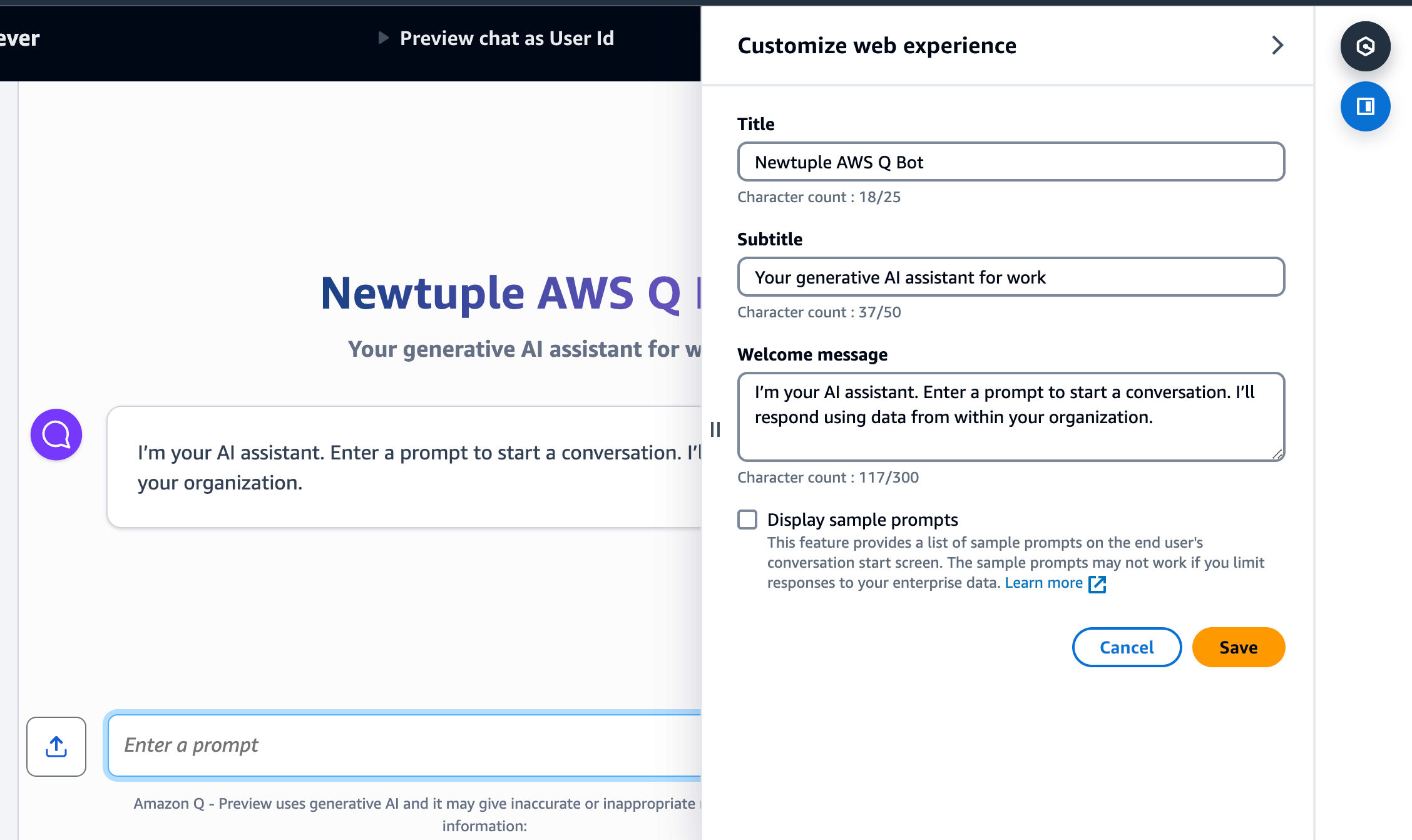
So what's the (very early) verdict on Q?
This is AWS's own shot at getting a slice of the rapidly expanding market for GenAI apps within the Enterprise. The big cloud vendors are essentially picking up product & service ideas from the gen AI community - RAG based applications have been around for nearly a year now, and AWS, GCP are following the lead set by Azure in providing Generative AI capabilities to enterprises on top of their own data.
Overall, this is an offering with great promise for enterprises - I think offering a one stop AI app that accesses your enterprise data, and governed by the robust security & access control methods inside AWS is valuable. Although there are some rough edges to the way this is developed and deployed today, I can see this as being a great entry into GenAI for enterprises that are looking at a well structured way of getting into the AI wave. Plus, you can count on AWS ramping up on this offering over a period of time.
I'll end with this: For those of you who have been building GenAI apps, especially those that use RAG, none of these technologies or apps are new. However, what AWS (and Azure / GCP) is doing with this kind of offering is to bring to the mainstream some of the GenAI capabilities for an enterprise, by building in the capabilities of data security, role based access, and positioning it for the enterprise audience. "Your data is never used for training" is a key selling point, which all LLM vendors also say but AWS comes with the entire set of tooling and credibility in the enterprise.
Tags: