NEWTUPLE
OCR BENCHMARK · DOCUMENT-TYPE EDITION · 2026
We expected one OCR engine to win. 1,600 evaluations on Gaugetuple proved otherwise.
PaddleOCR, Docling, LlamaParse and Surya, graded against fixed ground truth across invoices, financial tables and mixed real-world documents. The strongest engine changed with the document every time, which is the finding most teams standardising on a single OCR have not priced in.
01 · INTRODUCTION
Why we benchmarked four OCR engines
Optical character recognition is the first step in almost every document-AI system. Before a model can answer a question about an invoice or summarise a financial filing, some engine has to turn the page into text, and the quality of that text sets a ceiling on everything that follows. Most teams choose an OCR engine the way they choose any component: they read a public benchmark, pick whatever sits at the top, and assume it will hold up across the documents they actually process. We wanted to test that assumption rather than inherit it. This builds on our previous evaluation of finance-friendly OCR tools.
To do that, we ran four widely used engines over the same body of documents and graded every output the same way. The engines were PaddleOCR, Docling, LlamaParse and Surya. The documents covered three families that stress an engine in different ways: clean invoices with predictable layouts, dense financial tables with multi-column totals, and a mixed real-world set drawn from the OHR-Bench corpus that spans academic, legal, manual and financial pages. Each output was compared against a fixed ground-truth answer on Gaugetuple, our evaluation platform, which returned a score from zero to one, a categorical verdict, and a tag describing the kind of error when one occurred. The full run produced 1,600 graded outputs.
The finding that shaped the rest of this report is that no single engine was strongest across the board. Docling led comfortably on structured documents and then dropped to third on the mixed set. LlamaParse, which trailed Docling on invoices, won the hardest category outright. PaddleOCR rarely finished first in any category and rarely failed badly in one either, which turned out to matter more than any single peak score. The sections that follow work through the results by document type, by failure mode, and by the operational cost of choosing the wrong engine for a given workload.
Results at a glance
| Docling | PaddleOCR | LlamaParse | Surya OCR |
|---|---|---|---|
| Structured-document leader | Most consistent across types | Wins the mixed set | Trails in every set |
| 0.98 invoices & tables | 0.16 smallest drop | 0.79 hardest category | 0.63 last everywhere |
The practical takeaway is that there are different OCR libraries that are suitable for different use cases
. Structured documents belong with Docling, mixed or unpredictable material is better served by LlamaParse or PaddleOCR, and PaddleOCR makes a sensible default whenever the document mix is unknown. The engine-selection guide later in this report turns that into specific rules.
02 · SCORE BY DOCUMENT TYPE
The ranking changes with the document type
The clearest way to see the result is to hold the engine constant and watch how its score moves across document types. When we do that, the order on the leaderboard does not survive the move from one document family to the next. An engine that reads invoices almost perfectly can sit in third place on a mixed corpus, and the engine that wins the hardest set is not the one that wins the easiest.
 x_grouped
x_grouped
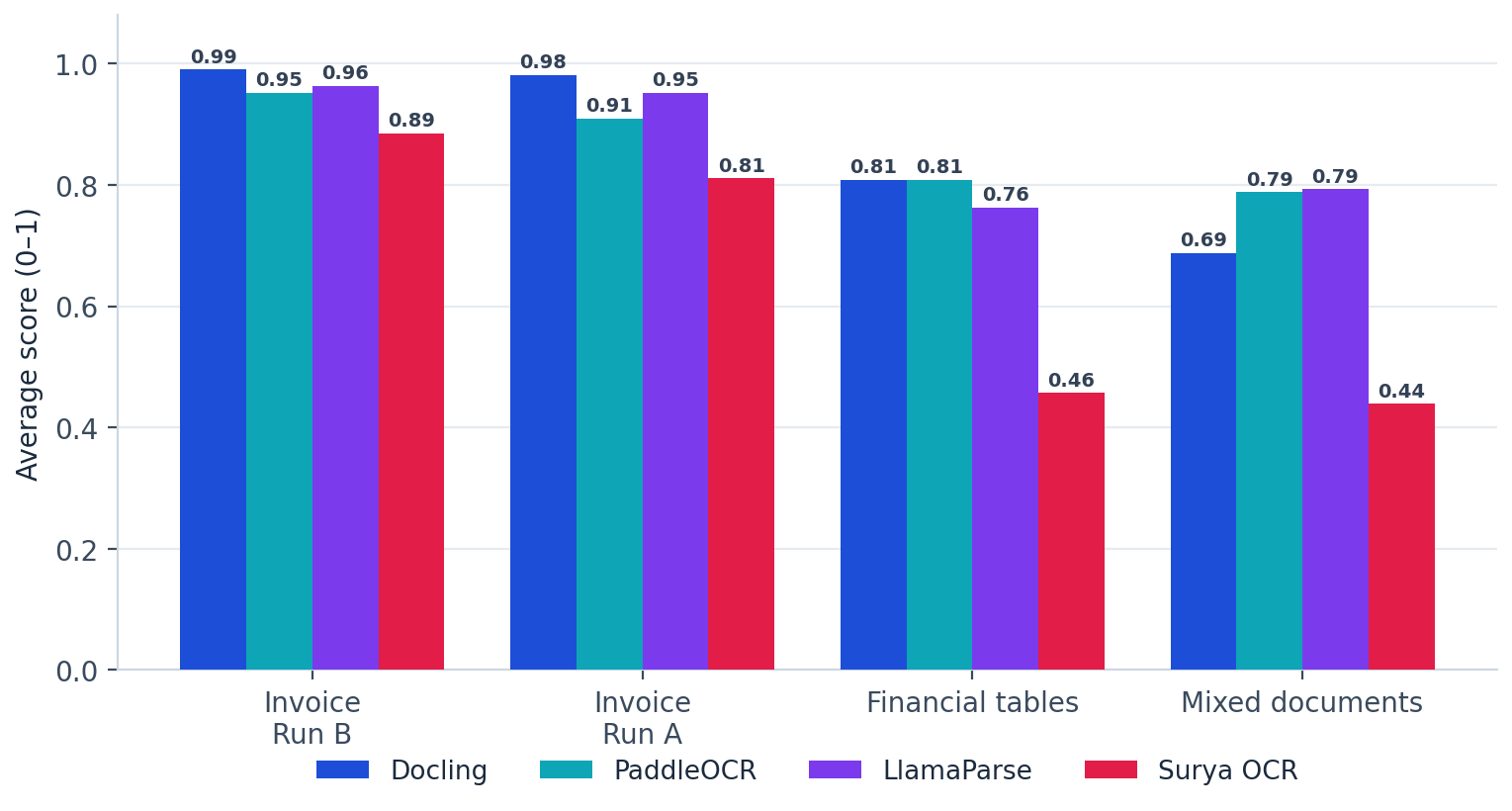
On invoices the four engines score within a few points of one another. On financial tables and on the mixed set the spread widens to more than thirty points, and the engine in first place is no longer the one that led on invoices.
| Document type | Maps to | 1st | 2nd | 3rd | 4th |
|---|---|---|---|---|---|
| Invoice · Run A | AP / procurement | Docling 0.98 | LlamaParse 0.95 | Paddle 0.91 | Surya 0.81 |
| Invoice · Run B | AP / procurement | Docling 0.99 | LlamaParse 0.96 | Paddle 0.95 | Surya 0.89 |
| Financial tables | Banking / reporting | Docling 0.81 | Paddle 0.81 | LlamaParse 0.76 | Surya 0.46 |
| Mixed documents | Enterprise / knowledge | LlamaParse 0.79 | Paddle 0.79 | Docling 0.69 | Surya 0.44 |
Industry mapping is approximate. FinTabNet is financial statement tables; the invoice sets are accounts-payable documents used across industries; OHR-Bench is a mixed corpus spanning academic, legal, manual and financial pages.
03 · ROBUSTNESS
PaddleOCR holds up best as documents get more complex
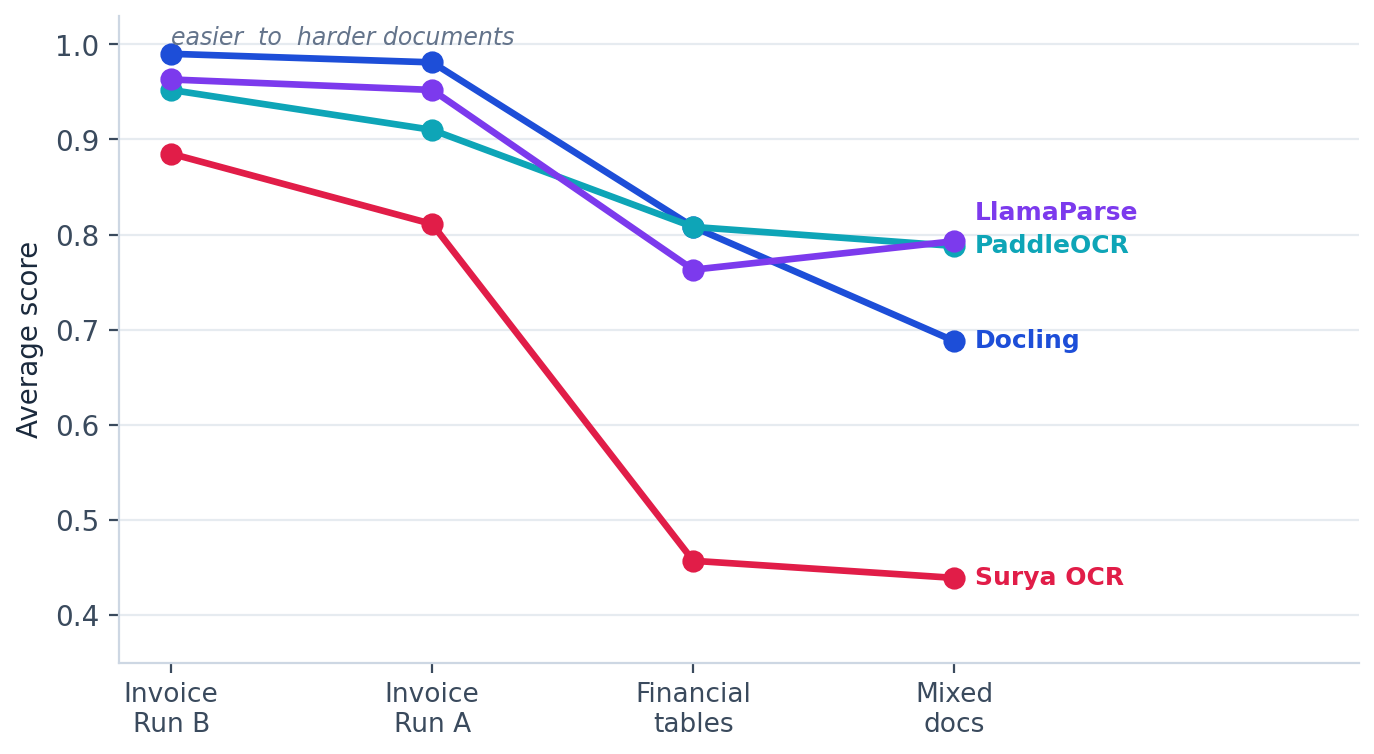
Peak accuracy on a favourable document type tells only part of the story. For a production pipeline that sees a range of inputs, what matters as much is how far an engine falls when the documents get harder. Ordering the four test sets from the easiest invoices to the most demanding mixed pages lets us read each engine as a trajectory rather than a single number, and the trajectories separate the specialists from the all-rounders.
 x_robust
x_robust
PaddleOCR has the flattest line and the smallest fall, losing 0.16 from its easiest to its hardest set. Docling starts highest of all but gives back the most ground among the leaders, a drop of 0.30. Surya starts low and declines by 0.45, settling at the bottom of every set.
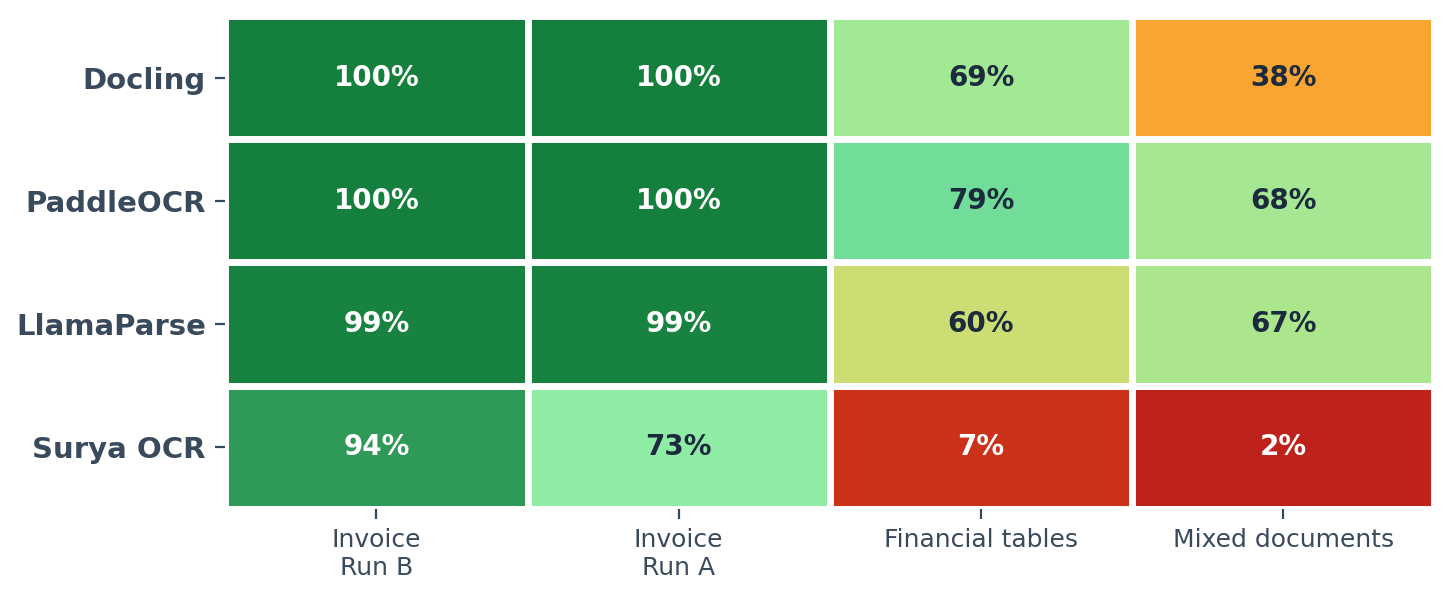 x_passheat
x_passheat
Pass rate counts excellent or good outputs. The story sits in the right two columns: on financial tables and mixed documents, PaddleOCR holds 79% and 68% while Docling falls to 69% and 38%.
04 · HOW FAILURES CHANGE BY DOCUMENT TYPE
Each document type fails in its own way
A lower average score does not explain itself. Two engines can land on the same number for very different reasons, and the kind of mistake an engine makes matters more for a downstream pipeline than the size of the score. When we group the tagged failures by document type, the documents are not simply harder or easier than one another. They fail differently, and the dominant error class shifts as the layout changes.
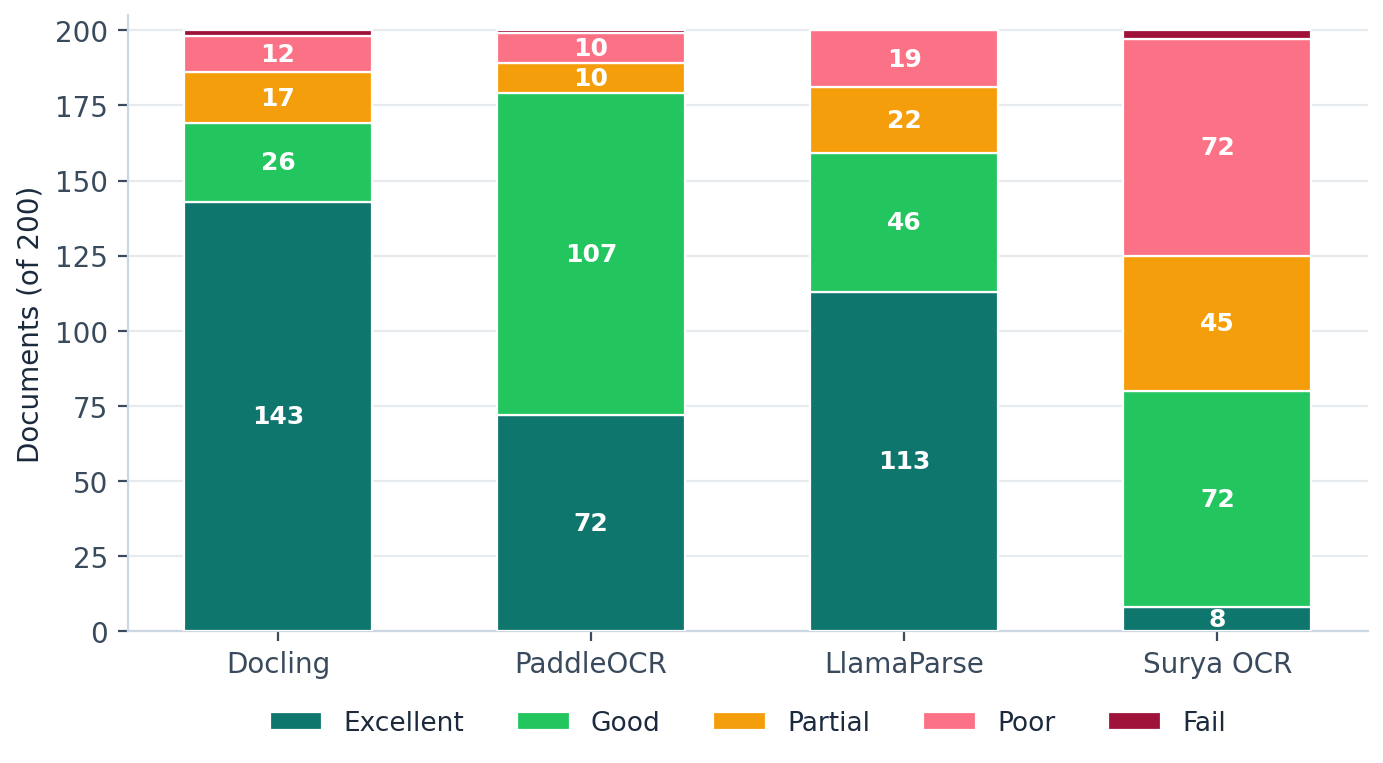 x_verdict
x_verdict
Verdicts for Invoice Run B are derived from score bands, because that run shipped without verdict labels. The other three sets carry the grader's own verdicts.
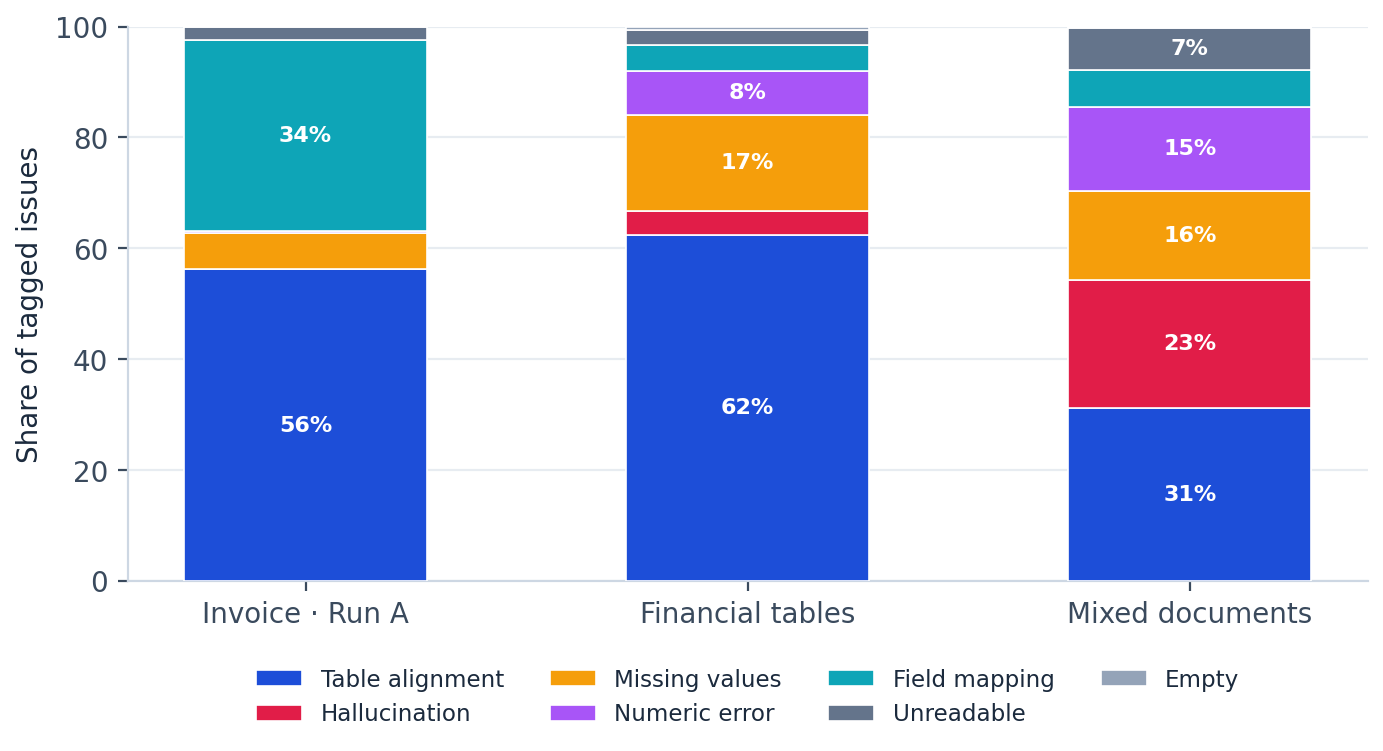 x_issuemix
x_issuemix
On structured documents the failures are overwhelmingly broken table alignment, where the text is read correctly but lands in the wrong cell. The mixed set looks different rather than simply worse: it introduces a large share of hallucinations and numeric errors, the two classes that are hardest to catch once the output moves downstream.
05 · CAPABILITY PROFILE
Strengths and weaknesses, engine by engine
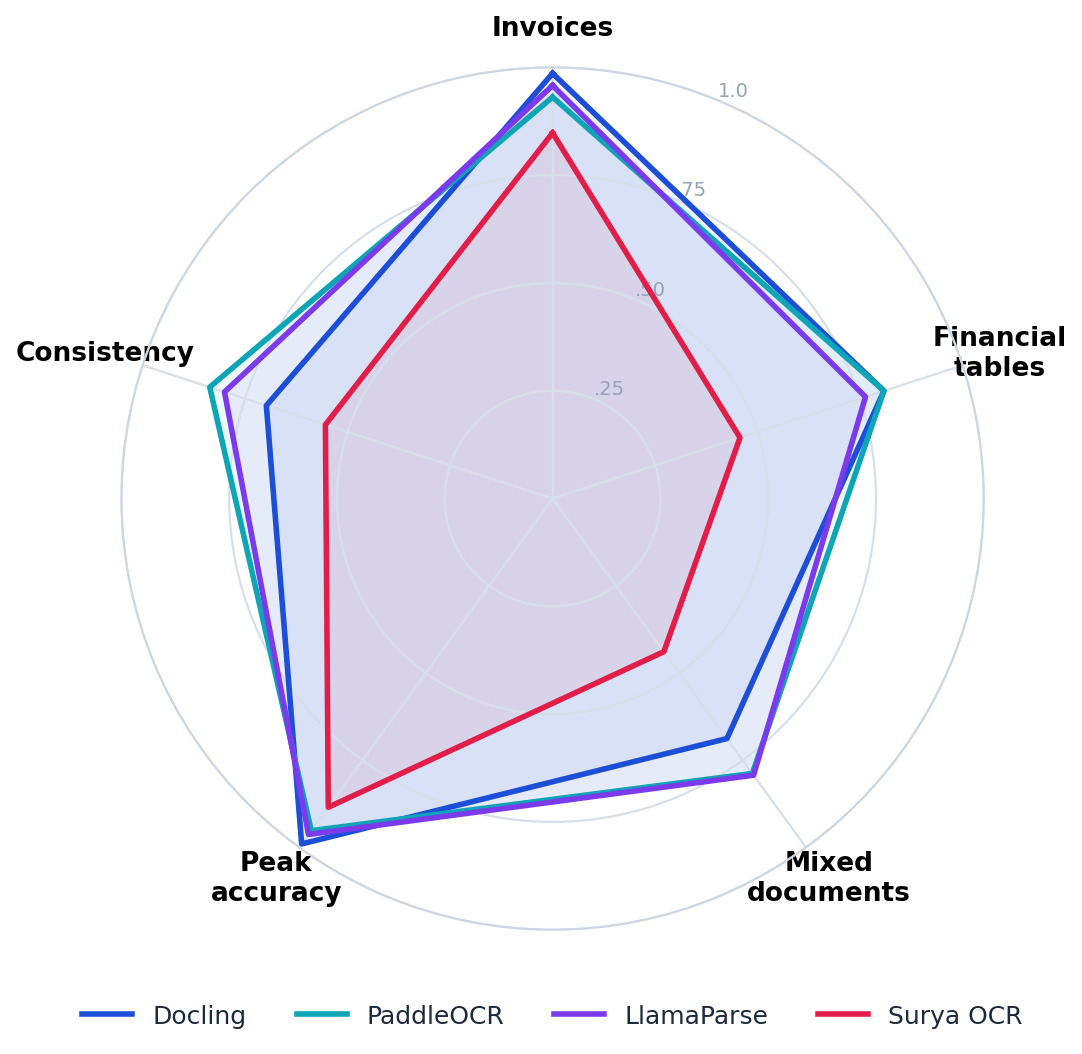 x_radar2
x_radar2
The radar plots each engine across five dimensions, all normalised to a zero-to-one scale: accuracy on invoices, accuracy on financial tables, accuracy on the mixed set, peak accuracy on its strongest document type, and consistency across all of them. Docling draws the widest shape on the structured axes and on peak accuracy, which reflects how well it reads invoices and tables, but it contracts on the mixed-document and consistency axes because its quality depends heavily on how predictable the layout is. PaddleOCR draws the most balanced shape of the four; it rarely reaches the outer edge on any single axis, yet it never collapses inward either, and that even profile is what makes it dependable when the input is unknown. LlamaParse reaches furthest on the mixed-document axis and stays strong on invoices, while giving back some ground on financial tables. Surya stays close to the centre on every axis, the visual signature of an engine that has not yet reached production quality on this workload.
| Requirement | Best engine |
|---|---|
| Tables / layout preservation | Docling |
| Invoices | Docling |
| Numeric accuracy | Paddle / Llama |
| Field alignment | Docling |
| Consistency / reliability | PaddleOCR |
| Mixed / unstructured documents | LlamaParse |
Roughly seven in ten outputs pass, and close to three in ten need correction. Across all four test sets and four engines, 72% of outputs landed at excellent or good. The remaining 28% carried a partial, poor or failed verdict, which is the review load any document pipeline has to plan around regardless of which engine leads on paper.
06 · BUSINESS IMPACT
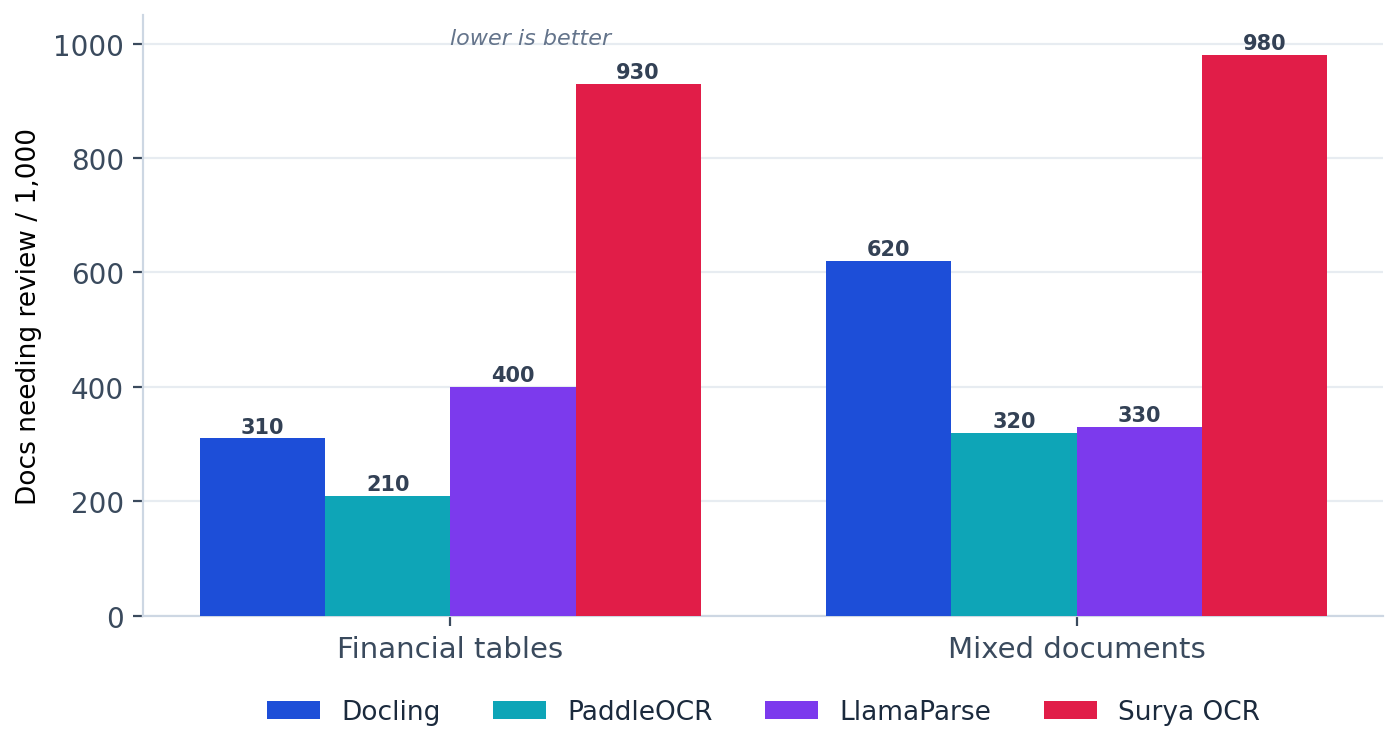
On mixed documents, the wrong engine adds 300 human reviews per 1,000
Accuracy scores turn into a budget line the moment they meet real volume. Any document that does not come back clean goes to a person, and people are the expensive part of a document pipeline. That makes the pass rate easy to read as a review load, where every output below the pass bar is one more document that someone has to open, check, and correct by hand.
On a run of 10,000 mixed documents, the gap between the best and worst mainstream engine is roughly 3,000 extra documents in the review queue, produced by nothing more than picking the engine that tops the invoice leaderboard and assuming it travels. On financial tables the same logic favours PaddleOCR over LlamaParse by about 190 documents per 1,000. Surya sends almost everything to a human on both types, which is why it stays out of production.
 x_reviewload
x_reviewload
Review load is the inverse of pass rate. Invoices are omitted because all mainstream engines clear them with almost no rework.
The saving comes from routing. Matching each document type to its strongest engine, rather than standardising on one, removes review load that a single fixed choice would quietly carry for the life of the pipeline.
07 · THE BIGGER PICTURE
OCR is the silent failure point in document AI
Most teams treat OCR as solved plumbing and spend their attention on the model at the end of the chain. The data argues the opposite. OCR sits at the front of every document-AI pipeline, and whatever it gets wrong is baked into everything downstream. A retrieval system cannot find a figure that was merged into the wrong cell, and a language model will answer confidently from text that was already garbled before it arrived.
The pipeline runs in one direction: Document → OCR (error introduced) → Chunk & index (error preserved) → Retrieve (wrong or missing context) → LLM answer (error amplified). An early mistake does not stay small; it travels.
The benchmark this report is built on, OHR-Bench, exists for exactly this reason: it measures how much OCR quality changes the answers a RAG system produces. A 0.69 OCR score does not translate into 69% usable answers, because the errors concentrate on the parts that carry meaning, the totals, dates, labels and table relationships. Those are the tokens a downstream model leans on most. This error amplification aligns with our earlier analysis of LLMs vs. cloud OCR.
This reframes what a team should be optimising for. The engine that matters is the one that preserves the structure and the numbers the rest of the stack depends on, which is a different target from raw character recognition. It also explains why the leader changed by document type in this study, and why a team building document AI is better off benchmarking OCR on its own documents than trusting a result built on someone else's.
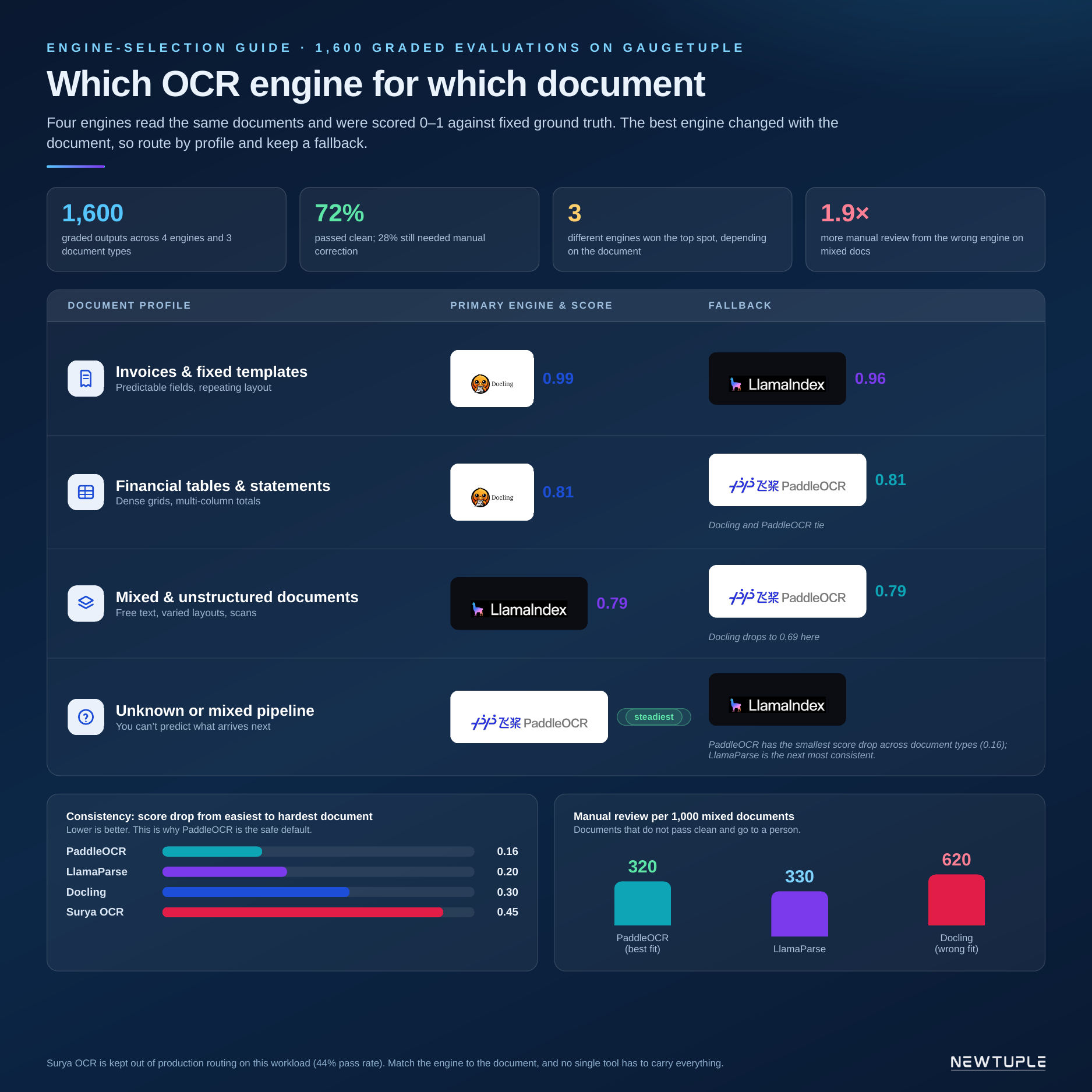
08 · ENGINE-SELECTION GUIDE
Which engine to use for which documents
The findings above translate into a short set of routing rules. Each document profile has a primary engine and a fallback, where the fallback takes over when the primary errors, times out, or returns output the pipeline flags as low confidence.
| Document profile | Primary | Fallback |
|---|---|---|
| Invoices & fixed templates | Docling | LlamaParse |
| Financial tables & statements | Docling or PaddleOCR | the other of the two |
| Mixed & unstructured documents | LlamaParse | PaddleOCR (avoid Docling alone) |
| Unknown or mixed pipeline | PaddleOCR | most robust default |
09 · ENGINE PROFILES
The four engines in detail
Docling structured-document specialist
Profile. It posts the highest peak accuracy of any engine on invoices and financial tables and produces the cleanest output on structured material. It is also the most fragile of the leaders, with a 0.30 drop from its easiest to its hardest set and a 38% pass rate on mixed documents.
Use it when. The layout is predictable and you control the document format.
PaddleOCR the all-rounder
Profile. It draws the flattest curve in the field, with the smallest fall across document types (0.16) and the best pass rate on both hard categories. It rarely tops a single category, and it never collapses in one.
Use it when. The document mix is unknown, or you want one dependable default across a varied pipeline.
LlamaParse the generalist
Profile. It records the highest average across all four test sets and is the only engine to win the hardest category. It is strong on invoices, weakest of the top three on financial tables, and prone to hallucinated fields that need a validation step.
Use it when. Documents are mixed or messy and a review step can catch invented or mis-mapped fields.
Surya OCR trailing
Profile. It places last in every test set, with the steepest fall (0.45) and pass rates of 7% and 2% on financial tables and mixed documents. It can read simple invoices but breaks down on structure.
Use it when. Lightweight or multilingual text, not dense tables.
10 · RECOMMENDATION
What to deploy across a document pipeline
-
Route by document type rather than picking one engine. The averages across all four sets are nearly identical for the top three (0.864 to 0.868), which hides the real differences. Per-type routing captures 3 to 30 points of accuracy that a single choice would leave on the table.
-
Docling for structured intake. Invoices, forms and financial tables go to Docling first, with LlamaParse as the fallback.
-
LlamaParse or PaddleOCR for mixed intake. Free-form and unpredictable documents go to LlamaParse, with PaddleOCR as the reliable fallback. Docling should not run alone in this lane.
-
PaddleOCR as the global default. When a pipeline cannot classify documents up front, PaddleOCR gives the most stable result across the full range.
-
Validate the high-risk classes everywhere. Mixed documents raise the share of hallucination and numeric errors, so add automated checks on numeric fields, totals and table row and column counts regardless of engine.
-
Hold Surya OCR out of production until its table handling improves.
Methodology and caveats. 1,600 graded outputs across four test sets and four engines, each output scored 0–1 by an LLM-as-grader against fixed ground truth. Invoice Run B shipped without verdict or issue-type labels, so its verdicts were derived from score bands calibrated on the labelled runs (99.3% agreement with the grader), and it is excluded from issue-composition analysis. Absolute scores are most reliable within a test set; cross-set comparison uses relative ranking, because Invoice Run B was graded on a compressed scale. Dataset-to-industry mapping is indicative rather than a controlled industry sample. All figures were recomputed directly from the source files.
11 · HOW WE RAN IT
How we conducted the evaluation
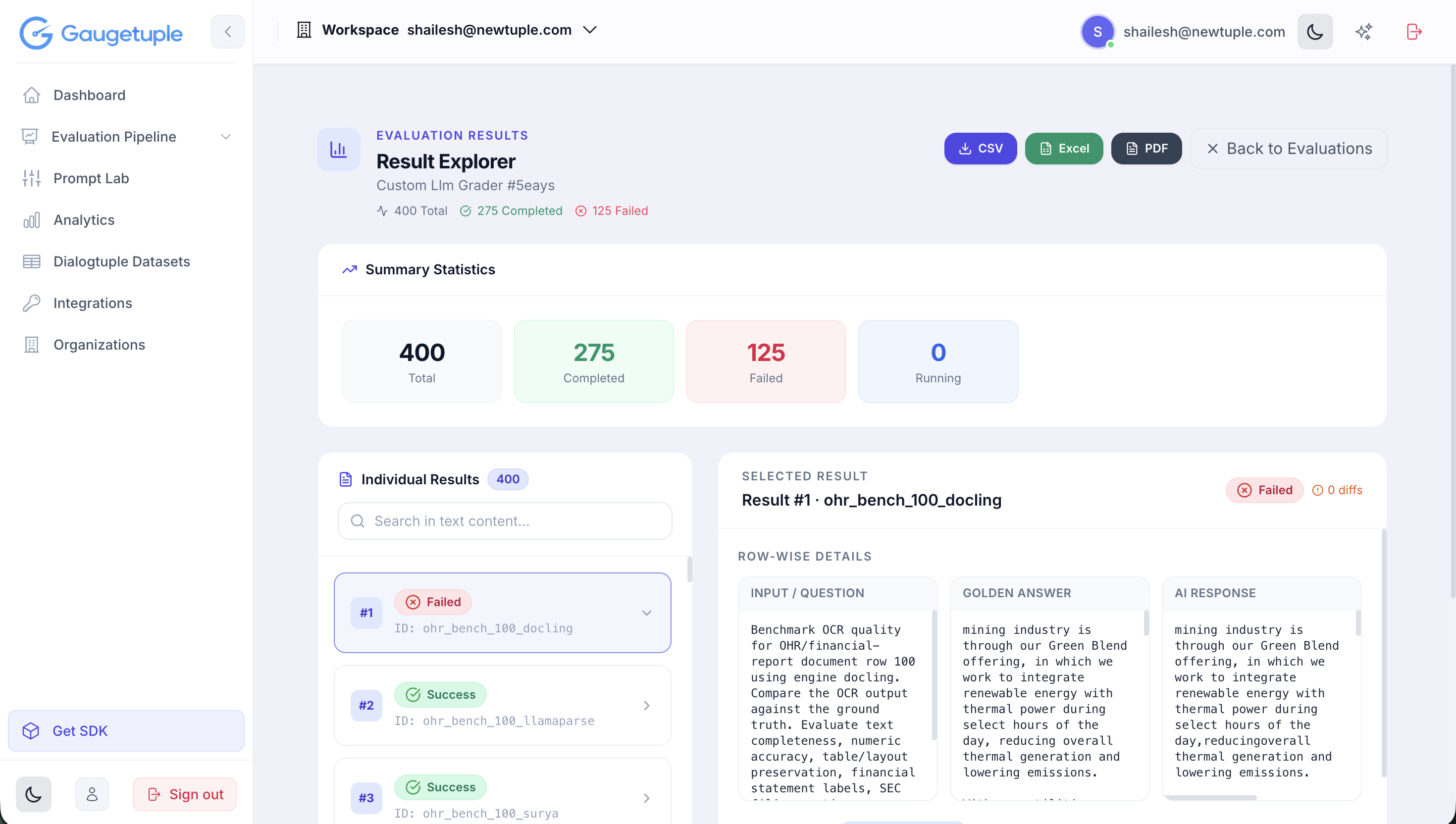
Every score in this report was produced on Gaugetuple, our evaluation platform, rather than read off by a person. For each document, the grader received the engine's output and the fixed ground-truth answer, then returned a score from zero to one, a categorical verdict, and a tag for the kind of error when one was present. Grading this way keeps the judgement consistent across 1,600 outputs and makes every figure here traceable back to a specific graded row. The screens below are taken from the same runs the analysis is built on.
 ss_results
ss_results
Result Explorer, run #5eays (OHR-Bench): 400 graded outputs, 275 completed, 125 failed, with each row's input, golden answer and engine output side by side.
 ss_eva
ss_eva
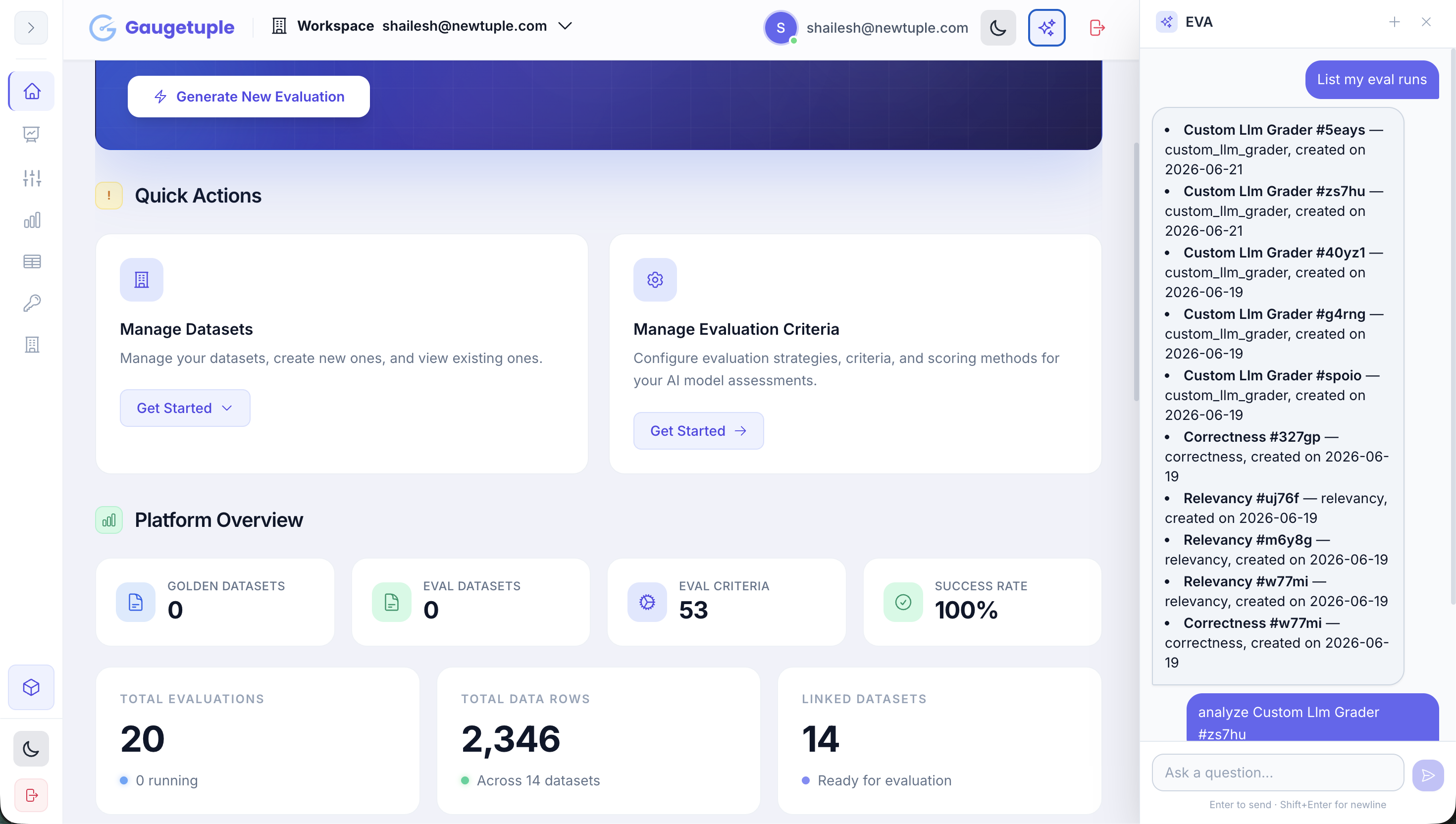
All three runs in one workspace: #5eays, #zs7hu and #40yz1, alongside the wider evaluation history across 14 linked datasets and 2,346 data rows.
 ss_fail
ss_fail
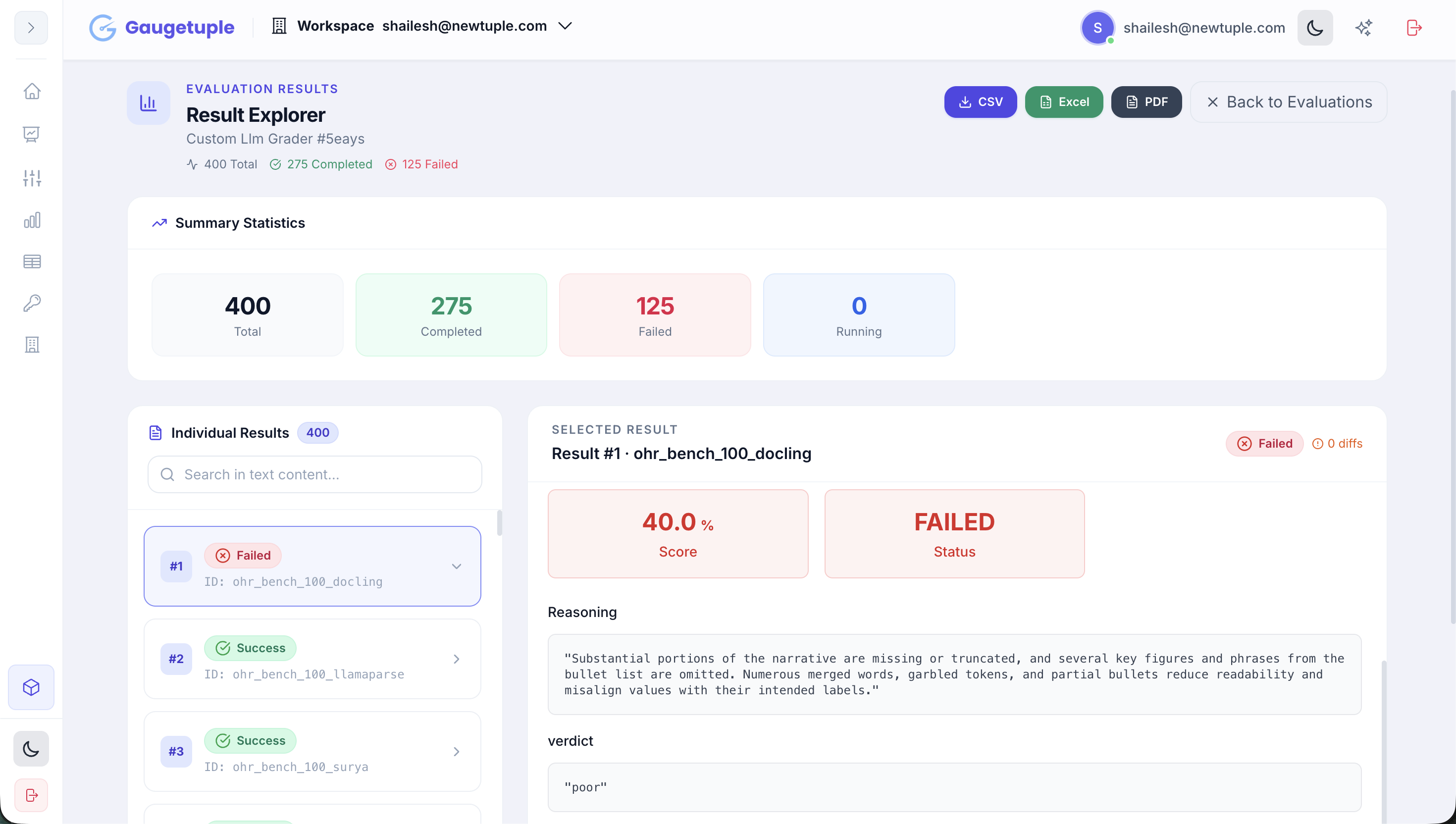
One graded result in full: Docling on an OHR-Bench page scores 40% and fails, tagged poor with the grader's reasoning.
 ss_suite
ss_suite
The evaluation pipeline: golden datasets, evaluation datasets, scoring configurations and run history that produced every number in this report.
OUR POINT OF VIEW
Choose the OCR engine on evidence
This started as a comparison of four engines and turned into a reminder about a component most teams stop thinking about too early. The quality of OCR quietly sets the ceiling for everything built on top of it, and three principles guide how we treat that at Newtuple.
Evaluate on your own documents. Public leaderboards rank engines on documents that are not yours. The order changed across our own test sets, so the ranking worth acting on is the one measured on the documents your business actually processes.
Route by document type. A single engine for everything leaves both accuracy and review hours on the table. Matching the engine to the document type, with a reliable fallback behind it, is what separates a clean pipeline from a growing review queue.
Re-benchmark as a habit. Engines and models change from one month to the next, so the evaluation that justified a choice last quarter is evidence with an expiry date. The measurement has to run on a schedule rather than once.
Newtuple builds and evaluates document-AI systems, and Gaugetuple is the platform we use to keep them honest. If you are choosing an OCR engine or grading a document pipeline, the same evaluation can run on your own documents. Start the conversation at newtuple.com.