In the last 6 months, we're seeing a clear shift in how organizations think about AI agents. Conversations with teams have moved from using agents as MVPs to thinking about how they operate at scale and in different situations.
The question is no longer "Can we build an agent?" it is "Can this agent reliably deliver outcomes in production?"
This shift is happening alongside a rapid increase in model capability. Models today are significantly better at reasoning, following instructions, and making tool calls. As a result, single-shot agents are surprisingly competent. Give them a well-defined task, the right tools, and a clean prompt, and they tend to perform well.
But the moment you move beyond that, when the agent has to operate across multiple steps, maintain continuity, or adapt over time, the same systems start to break down. Not because the model has gotten worse, but because the system around it was never designed to handle memory in a robust way.
That is where the real problem begins: context management.
The Problem We're Actually Solving
At a fundamental level, we're trying to build stateful systems on top of stateless models. This is easy to miss in demos and hard to ignore in production.
An LLM does not carry memory forward unless you explicitly provide it and each call is effectively a fresh start. But real workflows accumulate decisions, assumptions, and partial progress over time, and users expect the system to do the same. They expect continuity across steps, sessions, and outcomes.
This is also where things start to break in a very visible way. Systems that perform well in isolated runs begin to degrade as workflows get longer, missing earlier assumptions, recomputing work, and occasionally contradicting their own outputs. This is what I think of as agent amnesia, and it is not a bug but a direct consequence of how these systems handle context.
As interactions grow, the signal-to-noise ratio drops, irrelevant information creeps in, and important details get diluted, which means the system does not just slow down but becomes less reliable over time.
You can see this even in frontier tools. If you spend enough time in Claude Code, Cursor, or even a long ChatGPT session, the pattern shows up. Early interactions are sharp and consistent, but as the session grows, the system starts to miss details, lose constraints, and occasionally drift from earlier decisions. The degradation is gradual, but it is noticeable, and it has been well-documented: model performance systematically drops as conversation length increases, regardless of the model you use.
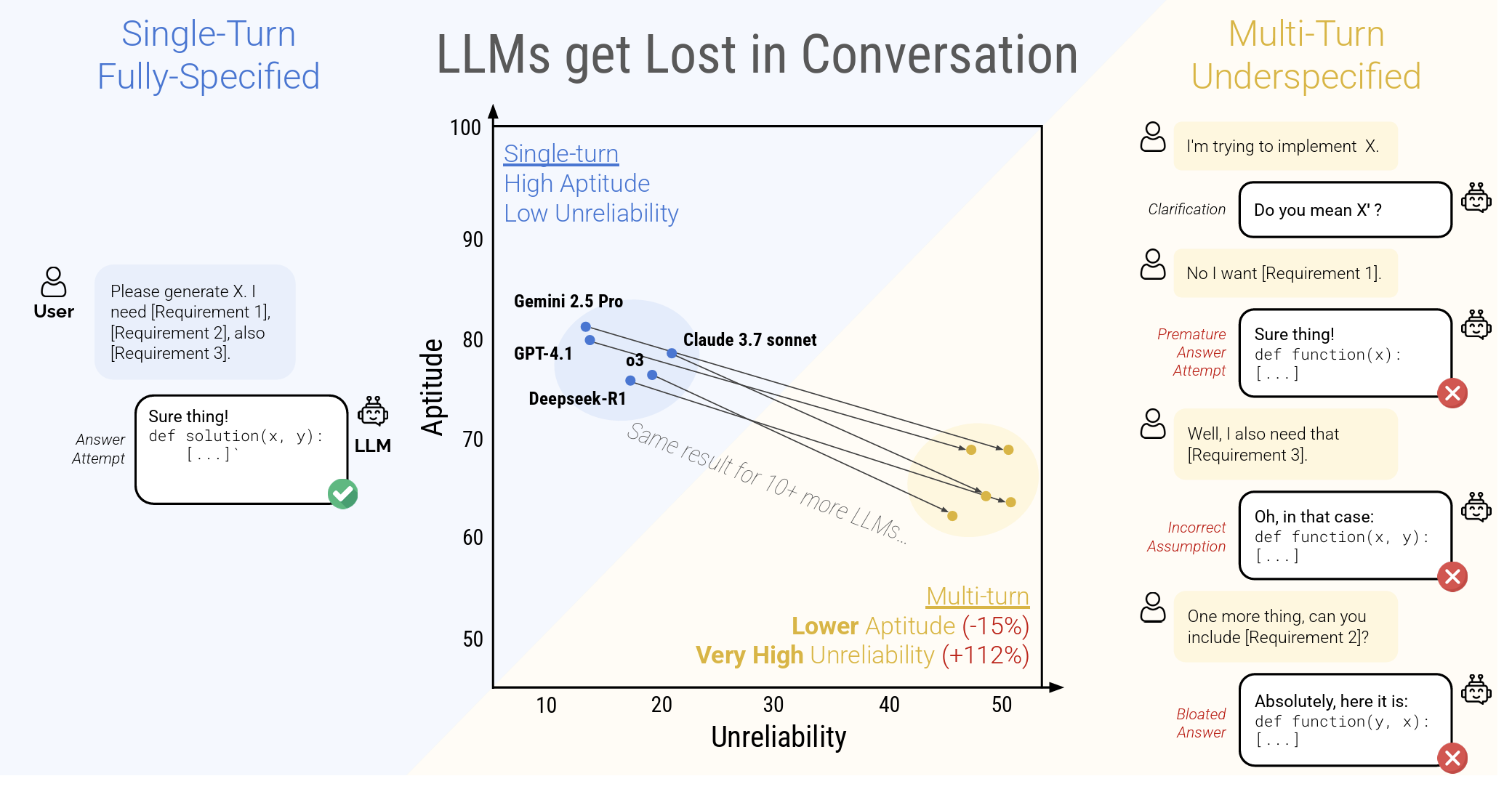 Performance degradation in multi-turn conversations. Source: LLMs Get Lost in Multi-Turn Conversation, arXiv:2505.06120
Performance degradation in multi-turn conversations. Source: LLMs Get Lost in Multi-Turn Conversation, arXiv:2505.06120
This tells us this problem is far from solved, even at the cutting edge. We are still very much at the frontier, and there isn't a single agreed-upon way to handle it. Different teams are experimenting with different approaches, each trading off control, flexibility, and reliability.
The problem is not just passing more tokens, it is introducing and maintaining state across interactions in a way that is selective and reliable, which requires deciding what to carry forward, what to compress, and what to discard.
It's a bit more tricky than it seems.
Context Management Defined
We often describe context management as "memory," but that framing is a bit too loose to be useful when you're building real systems.
A more practical way to think about it is this: context management is the layer that decides what information the agent should carry forward, what it should retrieve when needed, and what it can safely ignore. It is not just about storing data, it is about making continuous decisions under constraints, where the type of memory, how it is stored, and when it is retrieved all shape the agent's reliability.
In most systems, this context shows up in a few distinct forms:
- Immediate context: the current interaction, which acts like working memory and shapes the response in front of you.
- User context: preferences, history, and past behavior, which is what makes the system feel consistent over time.
- Organizational context: documents, workflows, and business knowledge, often large, messy, and constantly changing.
- Execution context: what the agent has already done, which becomes critical in multi-step workflows where continuity matters.
These layers behave very differently, and that is where a lot of systems run into trouble. Treating all context as a single blob to be passed into the model usually works at small scale, but breaks quickly as complexity increases. One of the decision points for creating a good solution for your application depends on how much priority you'd want to give to each of the above, during an agent's interaction with the system.
The Approaches We See and Work with Today
There isn't a single dominant solution to context management yet. What we're seeing instead is a set of evolving approaches, each solving part of the problem.
File-Based Context
One approach that's gaining traction is file-based context management. Instead of keeping everything inside the prompt, the agent reads from and writes to files as it executes tasks, effectively externalizing memory into a persistent layer outside the context window.
In practice, this pattern moved into the mainstream through tools like OpenClaw and Claude Code's agents.md, where instructions, constraints, and evolving state are written explicitly and updated over time. The shift is simple but important: memory becomes visible and controllable rather than hidden inside prompts.
Most systems we are working on don't need entire files on every step. They combine file-based storage with selective retrieval, pulling only the relevant sections into the prompt based on the current task. In other words, this is not just file-based memory, but file-backed memory with retrieval on top.
Teams typically make this work with a small set of disciplined patterns:
- Use a predictable structure for memory files so the model reads consistently
- Keep context tight through periodic compaction or summarization
- Access memory through search rather than full-file loads
In practice, that search often looks like:
- Grep-style keyword queries over files
- Lightweight semantic search on top of file content
- Hybrid approaches that combine both depending on the task
The goal is simple: fetch just the snippets needed for the next action, not the entire file.
Where this approach shines is in workflow-heavy systems. You get continuity across steps without depending entirely on the model's context window, and debugging becomes easier because you can inspect exactly what the agent "knows" at any point in time.
At scale, new constraints show up. Continuously reading and writing to file systems can get expensive, especially when agents rely on dedicated compute for file access. Two directions are emerging to address this. One is agent-oriented file system abstractions like those built on top of just-bash, which present a familiar file interface to agents. The other is cloud-native mounting, where object storage (for example, S3-backed file systems) is exposed as a CLI like interface so agents can interact with large remote file datasets as if they were local.
In both cases, the goal is the same: keep the developer and agent experience simple, while pushing storage, indexing, and access complexity into the underlying system.
So while file-based context gives you control, it also turns memory into a system you have to design and maintain, not just something you pass into a prompt.
Structured Context (Conversation Memory)
This is the most familiar approach and for a lot of teams it is where context management starts.
The basic idea is simple. You maintain a history of messages and pass relevant parts of that history back into the model. In the early LangChain style of implementation, this often meant something very straightforward: load the last n messages into the prompt and let the model infer what matters from there. LangChain has since evolved toward more stateful short-term memory patterns, reflecting how the field has matured.
That worked reasonably well for simple conversational systems. It was easy to implement, easy to understand, and good enough when the interaction stayed short.
The problem is that these histories grow quickly. Once the conversation becomes longer or more task-oriented, the prompt starts filling up with stale context, repeated details, and information that mattered three turns ago but no longer matters now. That is where compaction enters the picture.
Instead of carrying the full history forever, teams started introducing ways to compress or reshape it. In practice, this usually takes a few forms:
- Sliding windows: keep only the last n messages in the prompt (this is the most basic form of context management everyone started with)
- Conversation summaries: periodically summarize older parts of the interaction into a compact state
- Checkpointed state: persist the conversation or agent state outside the prompt and reload only what is needed at each step
Short-term memory is treated as part of the agent's state, persisted across steps, while compaction and summarization are used to stop the working context from growing without bound.
Where this approach shines is in conversational systems, especially when the conversation itself is the product. It maps naturally to chat interfaces, feels intuitive to users, and is relatively lightweight compared to more elaborate memory systems.
But it has limits. Structured context is still heavily dependent on the shape of the conversation, and once workflows become more complex, message history alone starts to become an awkward substrate for memory. It tells you what was said, but not always what matters, what changed, or what the system should carry forward.
So structured context is often the right starting point, but rarely the full solution once you move from chat into longer-running agentic workflows.
Retrieval-Augmented Generation (RAG)
RAG is often treated as the default answer to the context problem, especially when the system has to work across a large body of documents.
That framing is slightly misleading. RAG is best thought of as a retrieval layer for organizational knowledge, not a complete memory system. It works well when the challenge is fetching the right information, but less so when maintaining an evolving state across workflows.
The first challenge shows up in chunking. If chunks are too small, you lose context. If they are too large, retrieval becomes noisy. More importantly, semantic boundaries rarely align with fixed chunks, which means retrieval quality often depends more on how data is split than on the model itself.
There is also the issue of semantic drift. As documents change, embeddings evolve, and chunking strategies shift, the vector index can become inconsistent over time. Retrieval does not fail outright, but it becomes less precise.
Then comes scale. Vector databases grow continuously as new data is added and re-embedded. Over time, this creates pressure on latency, filtering, and cost, while also making it harder to maintain retrieval quality.
To manage this, most production systems introduce additional controls:
- Better chunking aligned with document structure
- Metadata and filtering to narrow retrieval
- Periodic re-indexing as the corpus evolves
- Hybrid search combining semantic and keyword approaches
RAG is very effective at helping an agent look something up. But it is much less effective as the sole mechanism for helping an agent remember what it has been doing.
Why You Should Build Your Own Context Layer
By this point, a pattern should be clear. None of the approaches we discussed fully solves the problem on its own.
File-based context is strong for workflows and execution state. Structured context works well for conversations. RAG is effective for large knowledge bases. Each one solves a different slice of the problem, and each one breaks in predictable ways when stretched beyond that.
The real decision is not which approach to pick, but how to combine them.
That is where building your own context layer becomes important. If you rely entirely on a framework or a single abstraction, you inherit its assumptions. Those assumptions may work for one use case and fail for another. As your system grows, that mismatch shows up as reliability issues, inconsistent behavior, or expensive workarounds.
Owning the context layer gives you control over those trade-offs.
- You can decide which type of context is handled by which mechanism
- You can route different tasks through different memory strategies
- You can evolve parts of the system without rewriting everything
More importantly, it forces you to be opinionated about context management.
What should be persisted versus recomputed? What belongs in files versus retrieval? What should be part of the working context versus long-term memory? These are not implementation details, they are design decisions that directly affect reliability.
In practice, most mature systems converge on a hybrid model, but the difference between a fragile system and a reliable one is how intentionally that hybrid is designed.
Building your own context layer is not about reinventing everything. It is about creating a clear boundary where you control how context is structured, retrieved, and applied across the system.
Once you do that, the rest of the architecture becomes much easier to evolve.
So How Do You Design Context?
Based on what we've seen building and deploying systems over the past 3 years, this is less about picking a tool and more about getting a few decisions right early.
- Map context to the job: for chat-heavy flows, message history is enough; for multi-step tasks, add a file-backed state; for knowledge lookup, add RAG. In most real builds we end up with all three, but only where they are needed.
- Make state explicit at boundaries: after each step, write down what changed in a stable place, then read it back before the next step. Teams that skip this end up recomputing or drifting.
- Keep the working set small: do not pass everything. Use search to pull the few lines that matter, or summarize older state. Systems that push full histories or full files into the prompt degrade quickly.
- Own the routing: decide which calls use history, which read files, and which hit retrieval. Hard-code this early. Letting a single abstraction handle everything is where most systems become inconsistent.
The goal is to design a coherent context architecture that stays predictable as the system scales.
Final Thoughts
In most systems we're working on today, the model is not the limiting factor. If anything, the models getting more powerful over time has moved the focus on context management.
This problem is easy to miss early on. In small workflows, everything works. The agent looks capable, even reliable. It's only when you push it into longer cycles and real usage that the cracks show. Details get missed, constraints get lost, and behavior starts to drift.
What looks like an agent or model problem today is usually a context problem. You're not just orchestrating a model. You're building a memory system around it.
The teams that get this right don't just build agents that work. They build systems that continue to work as complexity increases.